
Conversations often cover multiple domains. Multilingual conversations, sales conversations, switching to data entry information, and conversational AI with a multi-use case conversational flow are just a few examples where a conversation can switch wildly between domains within the same conversation. Customizing a single model helps, but using ensembles of targeted models instead of a single model can lead to even better performance. At the Conversational AI for Enterprise Summit, we welcomed Deepgram AI Speech Engineer Jeff "Susan" Ward to share insights into using custom model ensembles to improve multi-domain conversations.
Key Takeaways from the presentation and key quotes in this article include:
• What does it take to train several models
• Simple code to combine multiple models
• Results comparing a single trained model vs an ensemble of trained models
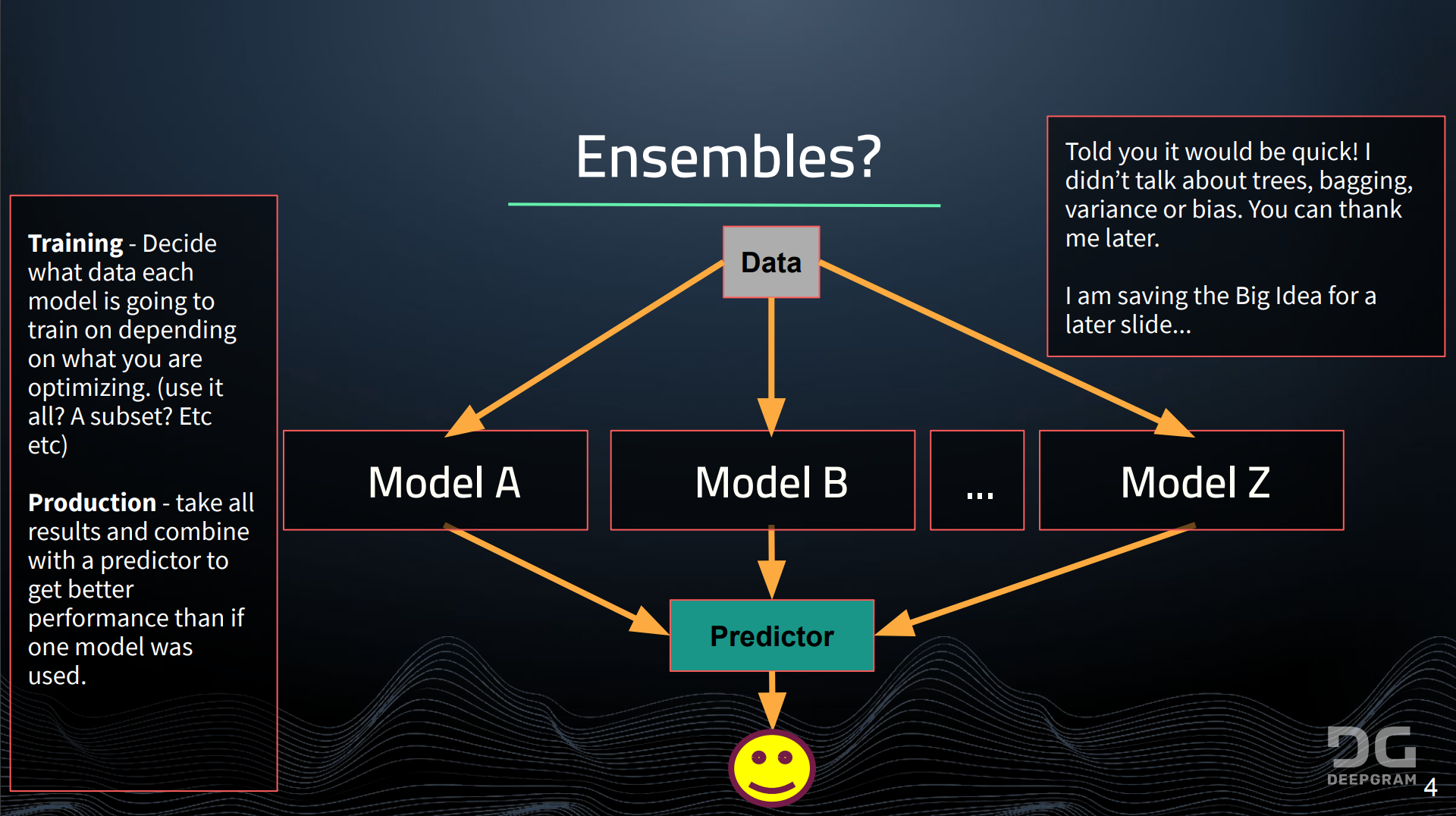
The Ensemble World
The important thing to recognize about ensembles is that there are really three big pieces: the data, the model and the predictor. For the data, the question there is how we're going to split it up during training, not during inference, but end training. How can we split that up to train the various learners that are inside the ensemble and then the predictor. How do we put them back together to get the best out of it?
What does it take to customize a model for a specific domain? When we talk customization, the reality is it's very hard to get a lot of single domain data. If you've got tens of thousands of labeled hours that's great, you're well ahead of the game. But the reality, in most solutions, they don't have that many. You have a few hours. So what we're going to do is start with a generally strong model and we're only going to take a couple of hours to start with. And we're going to specialize that model on that audio, and make sure that we hammer things like domain specific vocabulary and trying to get those engrams into the model that it really recognizes.
When I'm talking about training, I'm talking about the end to end training. Depending on how you've created your ASR stack, you could have multiple models evolve, e.g., acoustic model with a language model afterwards. When we talk about training, we talk about training the end to end. The whole thing gets hit with our training data. But the important thing to point out here is we are intentionally biasing the model. Our goal is to really make this model good at that domain.
Ensembles are generally thought of as a group of weak predictors that are put together to form a strong predictor. Another way to think is that we are combining strong domain specific performers that complement each other in order to form a strong multi-domain performer.
What are some common multi-domain situations? A big one that is very obvious is multilingual audio. Each language is a domain due to be targeted. The Conversational AI world has a lot of great multi domain examples. Each topic can be thought of as a domain inside of a conversational flow. Ordering solutions are a great example. You've got the products, the lingo of the company, versus the delivery instructions and the payment instructions.
How do you combine them? When you do an end to end transcription? ASR models generally know when they're out of their comfort zone. Every single stack is slightly different, but generally you can get a confidence score and the transcription as you're going along. And that confidence score drops dramatically when it's out of its comfort zone, especially two models that are trained using very similar technology. They're directly comparable without a lot of tough tricks to figure it out.
Multi-domain Example
Watch a 1-minute clip from Susan below:
What does an example look like? In this case, we've got three different strong domain predictors. We have highly targeted number domain prediction, and address domain and also an order domain for a fictitious ordering. So the user may be saying something like, "I would like fries and the chocolate shake. Please deliver to twenty five Gold Lake Road, Smallville". The general order predictor has a bit of general vocabulary in it, so it's going to pick up.
First of all, it's going to pick up the order correctly and it may know things like 'deliver it to' because that's more general. But it didn't really get anything about the numbers. It didn't get anything about the actual address. It kind of guessed address with Lake Road and Smallville, but it did so weekly because it's not confident at this point. The number of domain predictor was really strong on the twenty five, but it's weak on the two before it because it wasn't sure if that was a number or not. But being a strong number predictor, it weekly predicted that as opposed to strongly predicted that.

What should we take home from this?
Domain specific custom models regularly perform ∼10% better than general models with very little additional data.
Combining multiple domains allows even higher aims but with additional transcription costs. In use cases like multilingual audio, gains can be much higher which enables ASR to tackle tasks that weren't previously viable.
Watch the presentation in full from Susan here. Discover more from Deepgram here.
Discover more on AI applications in Enterprise at the upcoming Enterprise AI Summit, taking place in February in-person in San Francisco and online on 17-18 February. View the agenda here.
