
In this talk, Aparna Dhinakaran, Co-Founder and CPO of Arize AI, covered the challenges organizations face in checking for model fairness, such as the lack of access to protected class information to check for bias and diffuse organizational responsibility of ensuring model fairness.
Aparna also dived into the approaches organizations can take to start addressing ML fairness head-on with a technical overview of fairness definitions and how practical tools such as ML Observability can help build ML fairness checks into the ML workflow.
If you've heard of Michelangelo, Aparna built part of the model store, which was eventually kind of integrated into Michelangelo. After that, Aparna actually went to a Ph.D. program in Computer Vision, at which time she started thinking about things like ML fairness, how does bias get introduced into our models, especially models like facial recognition? At that point, as a researcher, Aparna was realising that she couldn't even answer basic questions about model performance or model service metrics. Simply put, there was just no way that Aparna could have been able to answer really complex and hard questions on model bias or model fairness. It was this time that Aparna was kick-started into building Arize.

Models, Information and Responsibility
First off, when you look at a lot of the tools available on the market, like Fairness Flow or IBM's kind of 360, a lot of them assume you have the protected class attributes available to look at and to look at kind of specific groups and measure these metrics. However, in the real world, oftentimes that data, when handed to modelers or by the time it is stored in some of these raw data platforms, it is often stripped of some of the original protected attributes. Alongside this, it often won't come neatly labeled with gender, age, ethnicity, etc. Due to this, some of these protected attributes might be missing or you may not have access to them.
There's actually a whole theory in regard to measuring fairness that if you don't include that information in models, it must mean that you're not biased.... Heads up, that's not true. But it's definitely one reason why these protected attributes are not given to the modelers. There's also a big debate around if this data should be provided. Is it violating privacy? It's a massive challenge. However, for this talk let's assume that you had access to that information.
As this is a fairly new phenomenon, there are also very few people who have the correct training to check for bias as there's no formalized practice, it's very new, very nuanced, and is being built as we go along.
There is often a trade-off between measuring these fairness metrics and understanding the trade-off that it could have on the business. In some industries, there could be a tangible business impact ensuring fairness. You have to ask, should I invest in this? Do we have the capacity and the team to do it well? Who would be responsible to ensure there's no bias? All this should be taken Into account.
Bias, Data, and Proxy
Another aspect you have to understand is where this data comes into play? An example of bias through a skewed sample would be historic crimes in certain neighborhoods. For example, it could see more dispatched officers because there was historically more crime rate there than for reported crimes in neighborhoods with a lower historical crime rate. These historically skewed examples are going to influence the data set that models are trained on, meaning they'll learn from that and decide, oh, I should dispatch more officers in X, Y, Z regions. This shows that historical skews are definitely a major factor causing bias and systems.
Another example is a human bias that's introduced in data. So, if you have a hiring manager who labels an applicant and decides their capability, what happens is that it's not only that the model's learning now, there's human bias that's also been added to that data set. So if that manager themselves were biased against certain gender or race, that bias will now be introduced into that data set. Even if you don't have kind of the protected class information within the data, if you're using things like sensitive attributes including the applicant's neighborhoods etc, this could indicate things like race which can also be used to learn this other kind of proxy. These proxies can basically be used to learn about sensitive attributes.

Thankfully, there's actually a lot of legislation around most of the protected attributes that we have today, things like sex, race, color, religion, disability status, veteran status. A lot of these are actually protected attributes that you legally cannot discriminate based off of this information. And the interesting thing is, is that this list might not be fully comprehensive. Aparna was talking to an organization that sells clothes the other day using models in one of the things they care about is actually size discrimination. So they want to make sure that based off of what this person has bought, they're not targeted for certain types of inventory or certain types of clothes. So it's very interesting because each industry might have certain of these protected attributes that are more important or more relevant and in other industries might be completely different.

Definition
What Aparna did next was talk through some of common fairness definitions. These are not at all kind of all encompassing or inclusive as there's actually a ton of researchers doing amazing work. We have 20, 30 definitions that are really common that are out there. But, at a high level at least, it's kind of go through and talk about individual metrics which give you an idea of kind of what can be used and the trade-offs of each. Through this, you start to paint a picture of which models might work and which ones might not work.
Aparna believes that the most commonly used model across industries is unawareness. If I don't include sensitive attributes in my model, then clearly my models aren't biased. There is nothing to learn also. This connotation also has one really big problem in that, models can learn off of proxy information that could hide this protected class, protected class information. And you end up bleeding in these biases without even being aware of it. And in some organizations, that's enough to kind of say this model's OK.

Class information, class attributes and medication
Let's talk trade-offs. What are the trade-offs your group Fairness is making, to ensure that people within different groups have the same things like representation or proportional representation? If you're suggesting that someone should be approved for a loan across the different groups, there's kind of proportional parity versus something like individual fairness, which is looking at individuals even across these different groups.
There's other ways, such as equalized odds, which means that you have two different groups, with equal chances of those within the groups to be qualified individuals to be approved or rejected. It's really interesting to try to understand where this one works better than something like individual fairness, through which we're doing high-level covers, and engaging counterfactual fairness. If you have one individual who's part of one group and they were evaluated and there was a label given to them, what label would have been given to them if they were tagged with a single different protected attribute? Obviously, in this case, just because that one label was changed, this person's outcome is changed.
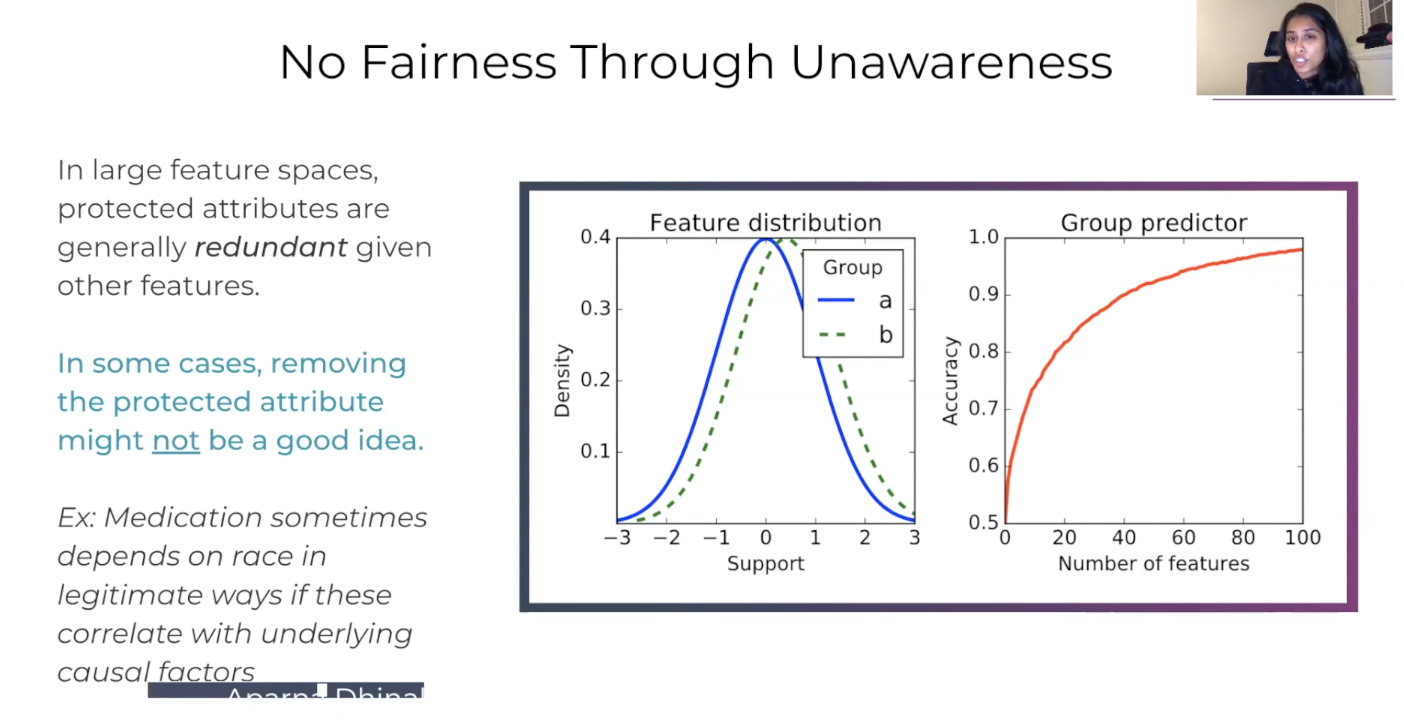
It's harder to do this in models where let's say you didn't even include that protected class information into the model. How would you have balanced switching the group label for this individual? This means you again have to dive in deeper into kind of what is unawareness mean if you remove some of this protective class information in as an input into the model, does that really solve your problem? Is that even a good idea?
If you have protected attributes, it's almost as if you just included the protected class information within the data set anyway. So in this case, this is kind of the group predictor, even with just a certain small number of features, you're still able to be accurate in predicting the group with just a small number of features. In the more and more number of features you add, you get closer and closer to basically having this protected class attribute figured out. So that's why unawareness is not often your be-all and end-all solution to tackling fairness. If it's correlated with a kind of underlying causal factors that impact certain groups more than others, then maybe you'd want that information so you can properly diagnose them and give them a necessary outcome.
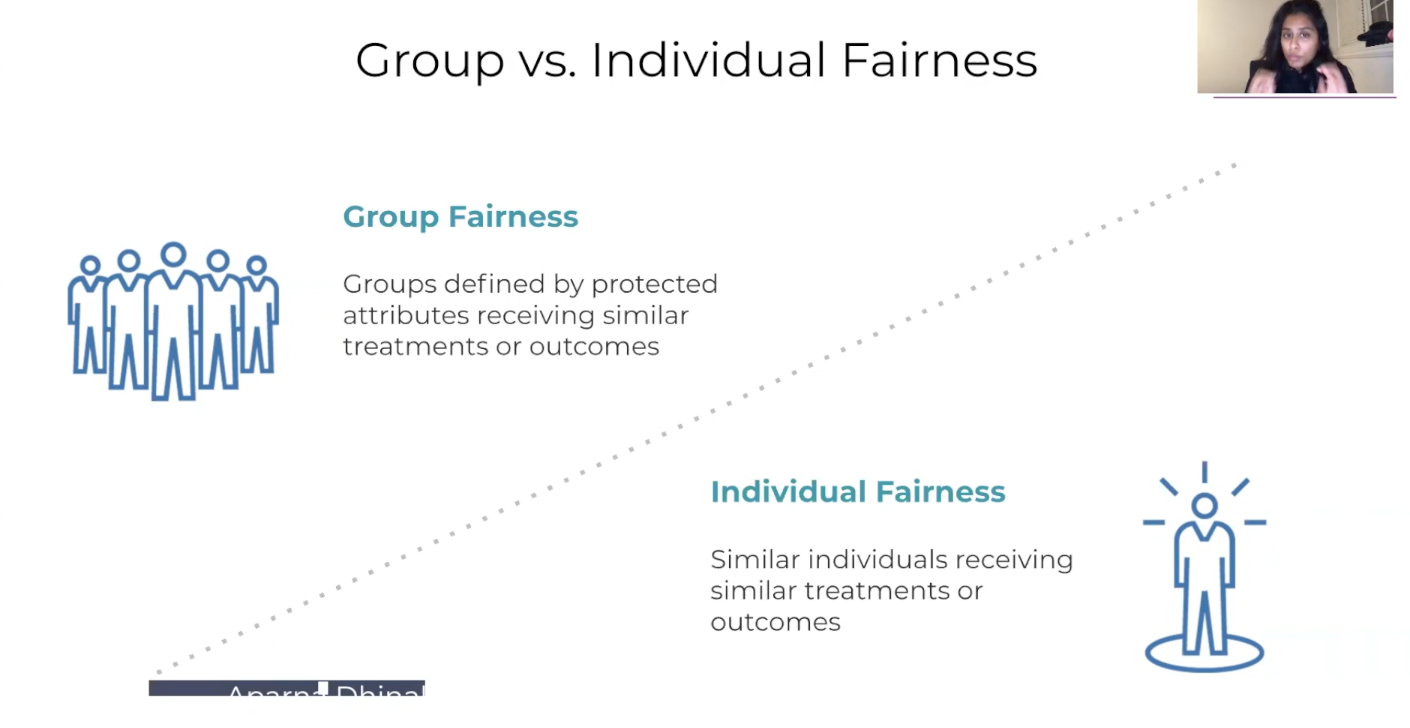
Metric, outcome, and Group B
Another thing Aparna wanted to discuss was the idea of fairness metrics dividing themselves into group fairness versus individual fairness. Group fairness is really thinking about group outcomes. You have group A and Group B, which are able to receive similar treatment or similar kind of outcomes, and so women should receive the same proportional or kind of similar types of labels as men do. You find very protected attributes should be receiving similar outcomes. It’s sometimes done through proportionality, sometimes it’s just through equal numbers. Then there’s another set of kind of metrics that call themselves a little bit more individual fairness, where you have similar individuals who should receive similar treatment or outcomes.
In reality, this method can be really hard to do, because even if you just think about what a lot of these models are trying to do, they are really taking a risk, based on some information about these individuals. So it’s not really a concrete kind of linear formula that you’re doing, so you are really taking a risk probability. In different industries, this would also be totally different. Identifying what makes two individuals similar can also be really, really tough.
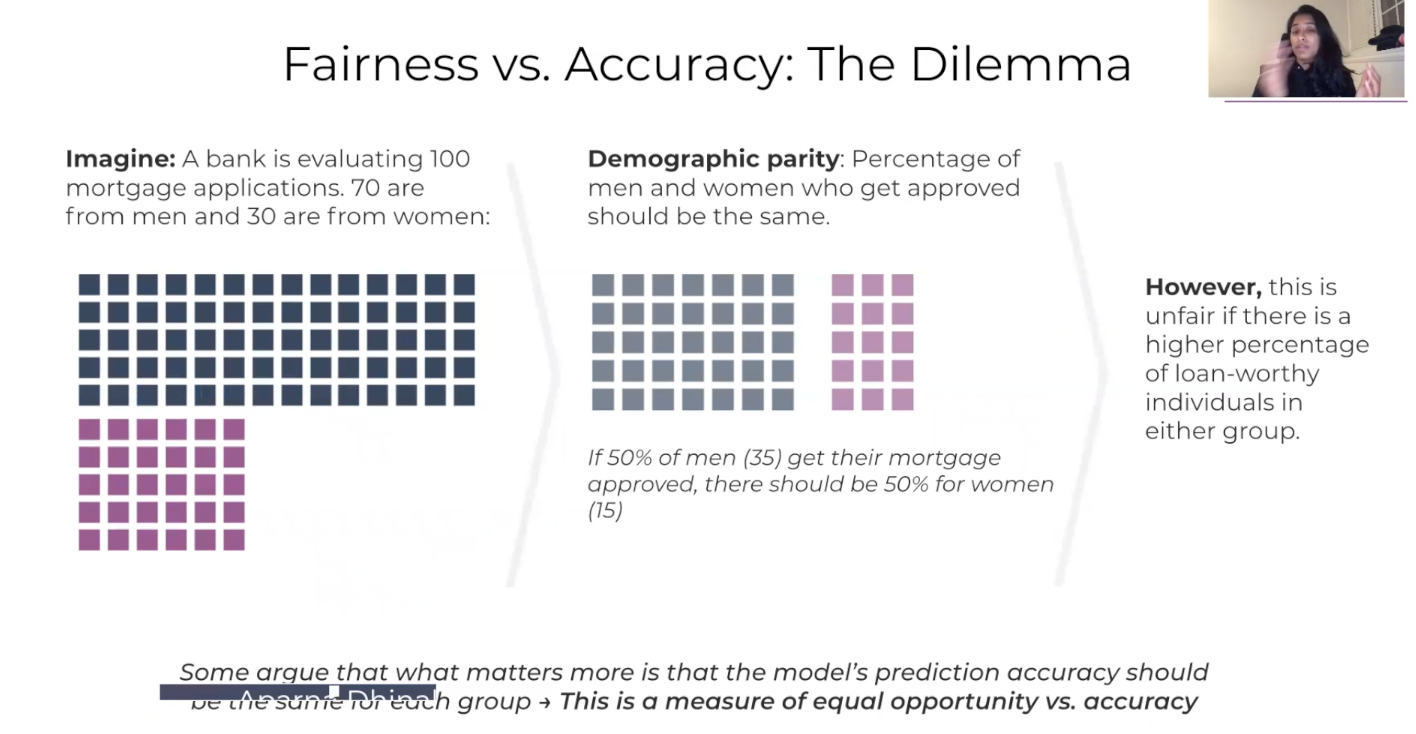
Mortgage, Loans and Percentages
To give you an example of a kind of group fairness and where’s an area where this might not be the right metric is at a bank. Let’s say a hundred different mortgage applications, 70 for men, 30 for women. If you think about something like demographic parity, the percentage of men and women who get approved should be the same. Let’s say 50 percent of men who get a reply should get their mortgages approved, and it should be 50 percent for women as well. This sounds great, except it could be unfair if there’s a higher percentage of loan-worthy, individuals in either group.
So let’s say there were legitimately more women of that 30 who applied, who were much more loan worthy, maybe shouldn’t just be 50 percent. But it really is a dilemma in the situation of what matters more. Is this really, truly fair? You want to make sure that representation really encourages equal opportunities, or do you want to make sure that the different errors that are happening in your model are balanced? This is worth diving into much deeper. But I just wanted to give you an idea of kind of how complex this can be to understand what metrics make sense for your model.
Metrics, Tools and Risks
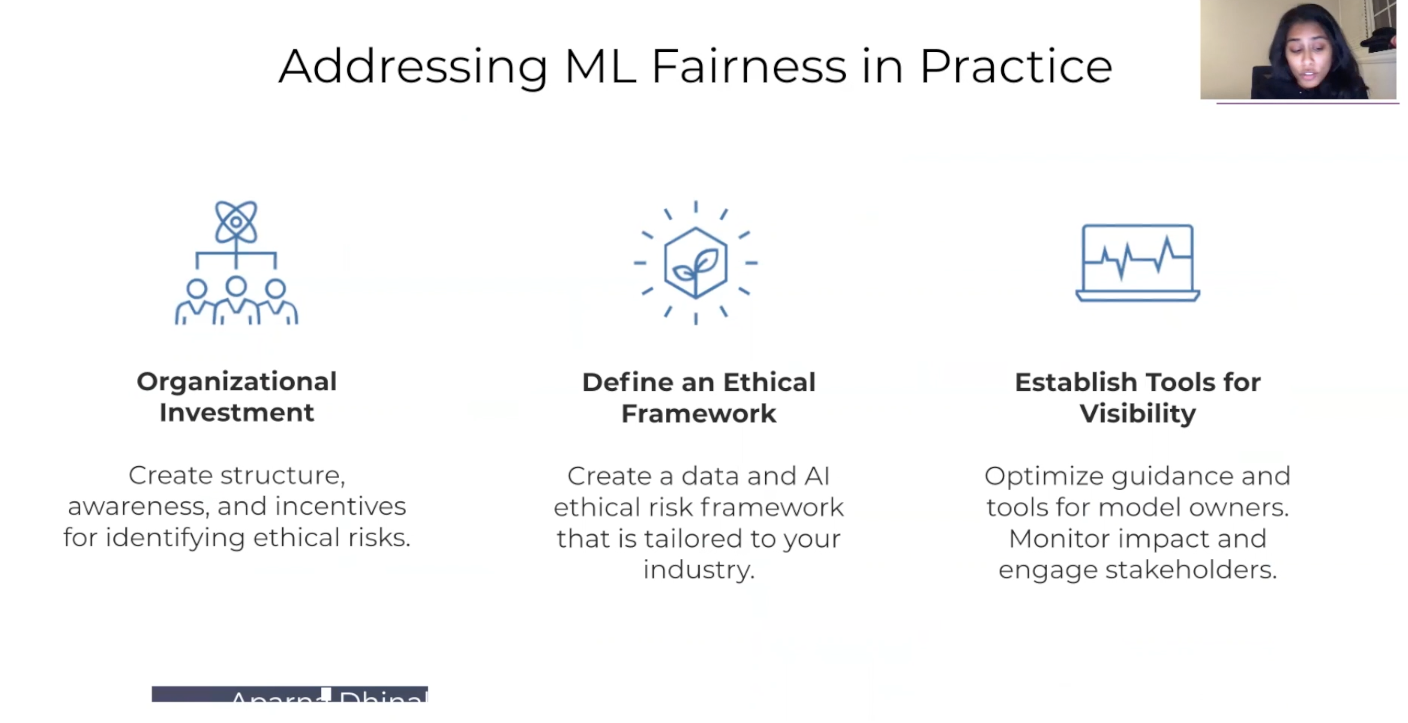
The next question is, how should you start thinking about bringing model fairness into your organization? I’ve broken this up into three kinds of groups. One is really an organizational investment. At an organizational level, there are people thinking about it in a similar way to your chief privacy officer, maybe deciding what the structure is, how often they’re going to be checked for things like your data security risks. Through this, it’s making sure that there’s structure, there are people in place to think about fairness, and then incentives for being able to identify or catch this kind of risk to the organization. The second thing to think about is defining this ethical framework. So even though different business problems can be different, identifying what is the right way to think about what metrics, what are we optimizing for, what makes how should we begin to frame the problem? I think a really important thing to do cross org as well.
Then lastly, of course, none of these things stay perfect. By having tools for visibility, having tools to monitor this or that, you can’t improve what you can’t measure. So having tools to get this and surfaces up is really important to keep it successful.
Model builder, perspective and Aminul Observability
What teams you're going to drive this with program? This is where Aparna found that she fit in with my interests. You can't find problems or find where these issues are if you are just shipping models blindly into production.
Is it good enough from a performance perspective? But is it also free of bias and not just catering to certain groups? No - you need someone driving this model and idea who understands, being able to measure this will make sure that whatever fairness pipeline that you do have, whether it's tackling that bias in the data through preprocessing or tackling it in training the models you know you're going to modify that outlook.
So thank you so much for joining the talk. I hope that that was useful and feel free to reach out if you have any additional questions. And we'd like to talk more. Thanks, everyone.
See the full video presentation from Aparna below:
Author bio:
Aparna Dhinakaran is Chief Product Officer at Arize AI, a startup focused on ML Observability. She was previously an ML engineer at Uber, Apple, and Tubemogul (acquired by Adobe). During her time at Uber, she built a number of core ML Infrastructure platforms including Michaelangelo. She has a bachelors from Berkeley's Electrical Engineering and Computer Science program where she published research with Berkeley's AI Research group. She is on a leave of absence from the Computer Vision PhD program at Cornell University.