
Lower precision & larger batch size are standard now
Over the past nine months, the deep learning community has substantially increased throughput capabilities for training neural networks. Factors like FP16 support and larger batch size are commonly-tuned parameters that can improve performance, but the TensorFlow framework is also evolving to make critical pieces of the pipeline more efficient behind the scenes. In this two-part blog series, we’ll first discuss the ways that precision and batch size impact performance, and then in Part 2 we’ll investigate how input pipelines affect overall training throughput.
Nine months ago, as part of a joint reference architecture launch with Nvidia, Pure Storage published TensorFlow deep learning performance results.
The goal of creating a joint architecture with Nvidia was to identify and solve performance bottlenecks present in an end-to-end deep learning environment — especially at scale.
During creation of our reference architecture, my team identified and improved performance issues across storage, networking, and compute. Our system is a physical entity, and everything from cabling configuration and MTU size to Tensorflow prefetch buffer size can impact performance.
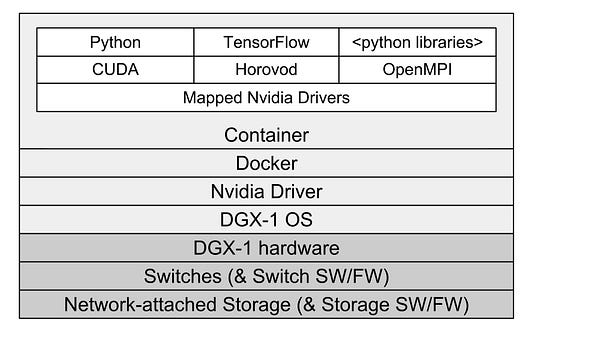
The software and hardware stack in our test environment. Each layer, and the seams between layers, can impact performance.
As a deep learning engineer, throughput on my AI test system has a huge impact on productivity. A 2.5x throughput improvement could mean going from a 3-day experiment to one lasting just over a day. While data throughput isn’t the only metric to optimize in a test system, it’s a good measure for improvement over time and across configurations.
Before and After
When we published our initial benchmark results in March, we tuned the system for what was optimal performance at the time. In particular, we found that there was large impact from how we structured the input pipeline (from storage -> GPU) in TensorFlow.
After tuning the configuration of the full stack from infrastructure to software, we were able to get a 42% throughput increase compared to the initial, default configuration found in the widely used Tensorflow benchmarks.
Over the past year, a multitude of work in the community has demonstrated that deep learning performance is constantly improving (we particularly like the ImageNet-in-4-minutes project). With developments both in new methodologies and in TensorFlow itself, the ML community has substantially advanced the software stack.
Repeating our full-stack benchmark tests today with the same hardware, we see a 2.5X performance improvement.
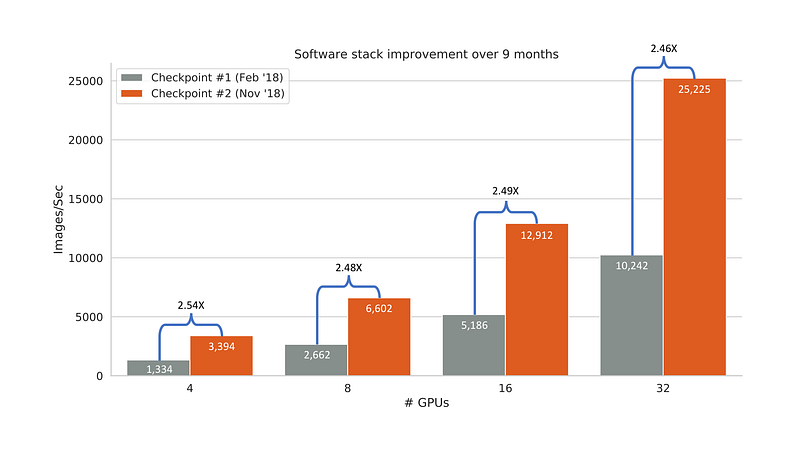
Throughput performance comparison across two points in time ten months apart. A key change between checkpoints was upgrading from Tensorflow 1.4.0 to Tensorflow 1.10.0.
Between these two checkpoints, my team didn’t change the models, dataset, or hardware.
For more about methodology and configuration specs, see this spec sheet.
How did we get 2.5X faster?
Because there are so many factors that combine to improve performance during training, it’s important for readers to understand that benchmark results are full stack comparisons. The 2.5X improvement seen here came from ten months of application developments, not a single factor.
For the performance gains we see today, we can group their sources into two buckets.
Part 1. TensorFlow is now better at handling lower precision & larger batch size jobs. We can handle more data and afford to perform more efficient operations like using lower precision for gradients. With FP16, developers can take advantage of Tensor Cores present on Nvidia GPUs, trading lower precision for higher training throughput. With larger batch sizes, more samples are processed together, amortizing coordination work.
Part 2. The input pipeline during training, previously a performance limiter, is more efficient. Performance results have improved overall as TensorFlow enables more efficient input pipelines and further workload-based optimization. Tuning the input pipeline can have a drastic performance impact; simply tuning the number of CPU threads dedicated to input pipeline work can result in a 1.5X throughput increase.
This post focuses on the first group: performance impact of FP16 vs. FP32 and of batch size 256 vs. batch size 64.
Part 2 will highlight key changes in the input pipeline that enabled further performance gains.
Factor 1: Better at FP16
Over the past few years, research has suggested that higher precision calculations aren’t necessary for neural networks. There is a trend of using FP16 (half precision) rather than FP32 (single precision) or FP64 (double precision).
The NVIDIA Tesla V100 GPU architecture introduced Tensor Cores, a type of processing core specifically optimized for mixed-precision operations.
“Storing FP16 (half precision) data compared to higher precision FP32 or FP64 reduces memory usage of the neural network, allowing training and deployment of larger networks, and FP16 data transfers take less time than FP32 or FP64 transfers.” [NVIDIA]
Today, deep learning training throughput can typically be improved by 1.5–2X by switching from FP32 to FP16 and keeping all hyperparameters the same. Direction & magnitude of weights is far more impactful than extensive precision of weights.
Today, deep learning training throughput can typically be improved by 1.5–2X by switching from FP32 to FP16 and keeping all hyperparameters the same. Direction & magnitude of weights is far more impactful than extensive precision of weights.
When new hardware innovations like NVIDIA Tensor Cores are released, it often takes time before software development occurs to optimize its utilization. In this case, Nvidia launched V100 GPUs in May 2017 and started shipping DGX-1 systems with that GPU model in November 2017. It wasn’t until May 2018 that FP16 was supported by the TensorFlow benchmark scripts — and it’s still in “experimental” mode.
Now that the full stack of GPU hardware + software libraries + application test scripts can utilize FP16 precision, our latest benchmark results can include that 1.5–2X precision-based throughput increase.
To highlight the impact of precision, we can compare results of the latest software stack + latest application scripts with FP16 and with FP32. FP16 gives the expected 1.5–2X performance boost linearly across number of GPUs.
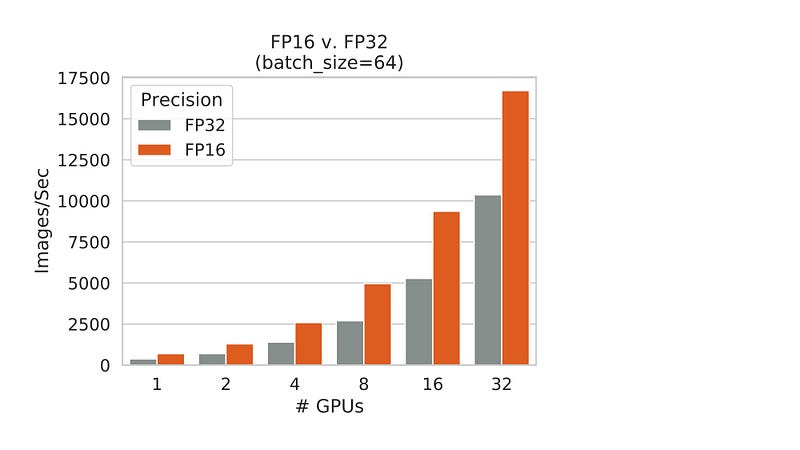
The improvement factor from FP16 is nearly flat as the system scales. There is a very slight decrease in improvement factor as we move into larger multi-node scale. We suspect that weakened improvement factor is due to the fact that GPU work takes up proportionally less of a batch’s time during FP16 jobs, which exposes the more inefficient non-GPU work (more on this in Part 2) at higher scale.
These precision-based performance improvements are applicable to most workloads. Frequently, training data collected by sensors or devices may be low-precision to begin with, so training with FP32 precision would be gratuitous. The switch from FP32 to FP16 is one that many development teams can make.
Factor 2: Better at larger batch size (256)
Another common way to affect training performance is to adjust number of samples consumed at once by GPUs. With an image dataset, each image will be read into CPU with information about its label–often via its parent folder name–resulting in 1 sample. During training, batch size is how many samples are passed to a GPU during the forward pass of computation.
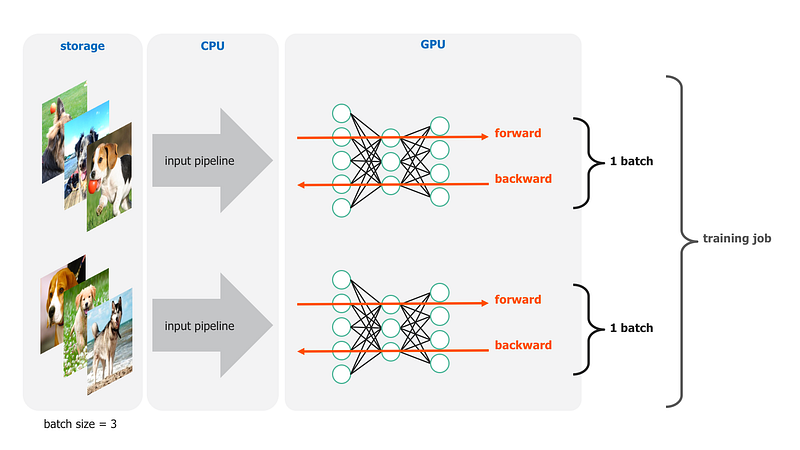
In general, the more samples processed during each batch, the faster a training job will complete. It’s not as straightforward as ramping the batch size up to 10,000, however. There’s a maxim that using a larger batch size requires an increased number of iterations to reach desired accuracy level. So, it’s important to find a batch size that fits the workload such that decreased time per batch outweighs increased number of batches required.
Aside: “Batch” or “Minibatch”? This post follows the convention where “batch” could be interchangeable for “minibatch” since we describe sample count, not gradient descent algorithms. (further reading)
Unfortunately, selecting batch size is not a simple process yet. For computer vision workloads that look like ImageNet classification, a team might start with batch size 64 simply because it’s a common starting point. Batch size 64 is, in fact, what’s highlighted on the TensorFlow performance benchmark homepage. Most teams experiment with various batch sizes and tune it like other hyperparameters. Tuning is impacted by both hardware (e.g. available memory) and workload implementation (e.g. precision, memory management).
For the past couple years, 256 was the high end of typical batch size, with 32 and 64 more prevalent. As one can imagine, there’s a memory limit on number of samples that can be processed by a single GPU at once. During testing on prior TensorFlow versions, memory constraints prevented us from executing resnet50 tests with a batch size of 256.
In the past year, performance for batch size 256 has improved to the point of making it more viable as a standard batch size. This development is especially true for models using small sample dimensions such as ImageNet + resnet50 (224x224).
In our testing, training throughput for jobs with batch size 256 was ~1.5X faster than with batch size 64.
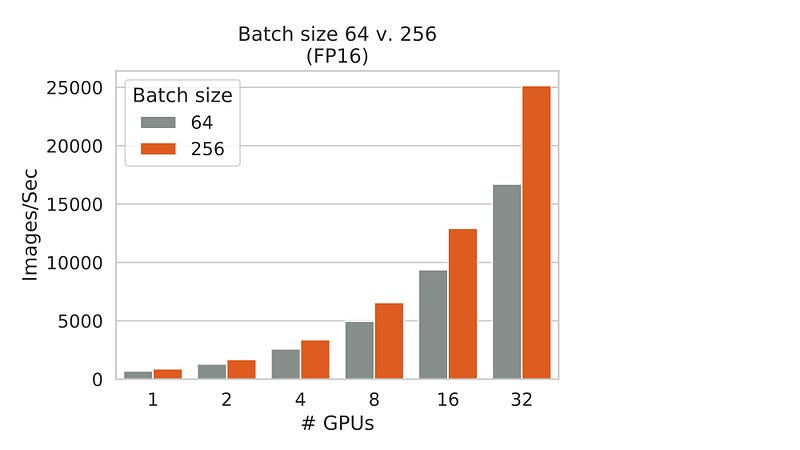
As batch size increases, a given GPU has higher total volume of work to perform. So, the overall training job has a higher proportion of non-GPU work than with smaller batch sizes. Since non-GPU work is less efficient than GPU work–which we’ll dig into further in Part 2–a 32-GPU job scales those inefficiencies and exposes the throughput limitations attributed to non-GPU work. This trend can be seen by the fact that the improvement factor between batch size 256 and batch size 64 isn’t static but rather increases linearly as GPU count increases.
In fact, we tested the throughput during jobs with synthetic data generated on the GPU, which removes most non-GPU work. As we compare these results to tests with real images, jobs with larger batch size achieve throughput closer to the synthetic “optimal,” “all-GPU” result. When a larger percentage of total time is spent performing GPU work, overall training throughput is closer to ideal.
It’s difficult to pinpoint the exact cause of increased memory efficiency due to complexity of a job–e.g. highly parallel work across multiple threads across multiple devices. We suspect scheduling improvements have been implemented that make better use of GPU memory. One possible approach is summarized in this blog post. We hope that, as more microbenchmark and debug tools develop, we’ll be able to better dissect scheduling tasks in the future.
Further, while we’ve significantly improved memory management for relatively small models like resnet50, it will be exciting to see how performance evolves for larger models. New tools like GPipe can help expand efficiency–and thus viability–of much larger models.
Where are we going?
We’ve seen that numeric precision and batch size are moving in a direction that results in more efficient throughput. Both lower precision and higher batch size can improve training throughput without changing other aspects of the model or development environment. These continue to be active areas of research, with interesting work such as single bit gradients and batch size of 8192.
Staying abreast of the latest trends in precision and batch size isn’t enough to get optimal performance from a deep learning training environment. Beyond memory management and use of Tensor Cores, there have been significant improvements in the TensorFlow ecosystem, especially around input pipeline performance.