
At the ML Fairness Summit, we welcomed Fiddler Data Scientist, Léa Genuit to discuss intersectional group fairness. As more companies adopt AI, more people question the impact AI creates on society, especially on algorithmic fairness. However, most metrics that measure the fairness of AI algorithms today don’t capture the critical nuance of intersectionality. Instead, they hold a binary view of fairness, e.g., protected vs. unprotected groups.
In the below blog, Lea covers the latest research in research on intersectional group fairness. Key topics covered include:
- The importance of fairness in AI
- Why AI fairness is even more critical today
- Why intersectional group fairness is critical to improving AI fairness
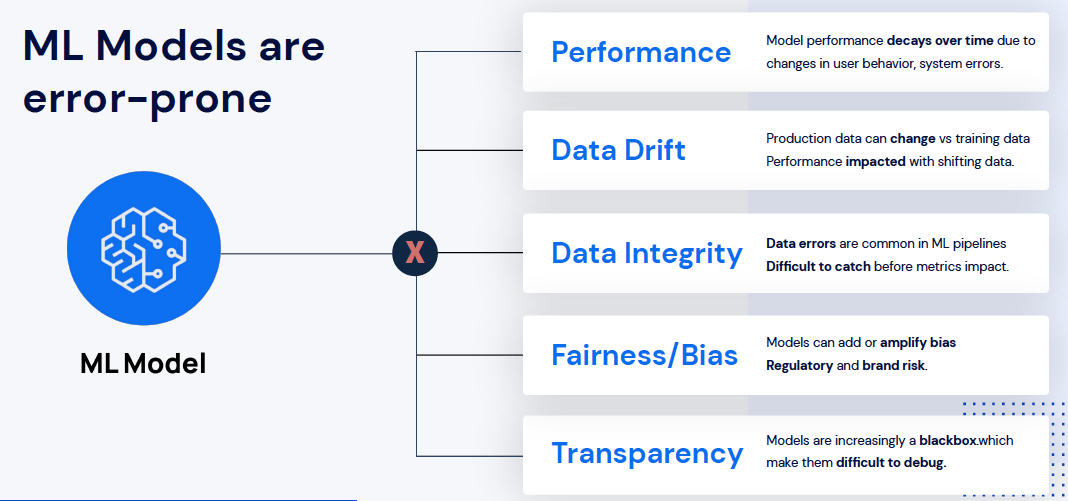
ML Models Prone to Error
Before explaining why, the first question should be how do you detect and mitigate bias in European models to avoid a bad experience? For example, I know you may have heard about the Apple case and Gender discrimination complaints against J.P Morgan which was federally settled for fifty million dollars. Machine Learning models are often biased. The main issues currently faced by ML models are:
- Wavering performance over time, decaying due to changes in use behaviour or system errors
- Data Drift - Production data can change vs training data - performance impacted with shifting data
- Data Integrity - Data errors are common in ML pipelines. It's difficult to catch before metrics impact outcomes
- Fairness/Bias - Models can add or amplify bias. Regulatory and brand risk
- Transparency - Models are increasingly a blackbox which make them difficult to debug
This can be due to a variety of complex causes like pre-existing social bias and imbalance training, data set, etc. For example, there is currently software used across the United States to predict future criminals and this is suggested to have strong racial bias.

An example of this was first found back in 2016, showing that the algorithm used for recidivism predictions produced much higher false positive rates for black people than white people. Interestingly, these algorithms were used to make informed decisions on who can be set free at every stage of the criminal justice system. In the above image you have two people, both with one prior offence. On the left of the image you have the one man who has three subsequent offenses. But the algorithm gave him a lower risk of three and on the right side of a black man when no subsequent offenses got a higher risk more often.
So the question is, will you trust such a system?
“On artificial intelligence, trust is a must, not a nice to have. With these landmark rules, the EU is spearheading the development of new global norms to make sure A.I. can be trusted.” - Margrethe Vestager, European Commission
Intersectional Group Fairness
With that in mind, let's talk about what is intersectional group fairness, understood to be Fairness along overlapping dimensions including race, gender, sexual orientation, age, disability, etc. It's not just binary protected classes vs protected classes. It takes into account multiple dimensions.
We (Fiddler AI) came up with a framework to measure fairness, and this is what we call the worst case disparity framework.

It's what we call a watch in principle of distributive justice. So first up, you're going to select a furnace metric. After this, you're going to compute this fairness metric for each subgroup, if we take again the same example than before, and we have both race and gender as predicted attributes, you compute this fairness metric for each of the groups. And then to give you an idea about how the model is performing in it, like the disparities among the subgroups.
Having done this, you compute what we call the Min max ratio, which is just taking the minimal value that you obtained by the maximum value and the IDB in the middle min max ratio is that we want to give like a ratio close to one. If this happens, it means that all of the subgroups have similar values for the selected fairness matrix, meaning that you don't have to set priorities.
So, how, when and where can we use intersectional fairness to improve our isolation that comply with regulation and build trust in the eye? That's the question.
Model Performance Management
Recently we introduced what we call a model performance management framework. Which suggests establishing a feedback loop in the Machine Learning lifecycle to help data scientists improve models more efficiently.
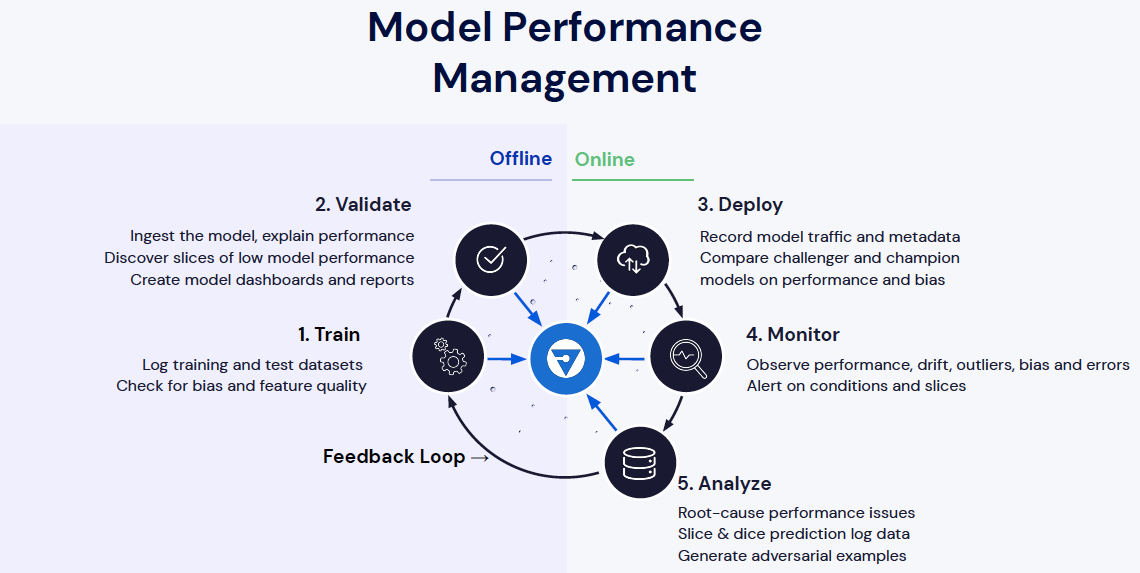
You probably are familiar with the above diagram, whereby you have an offline step, during which you train and validate your model, and then you go into online, where you deploy your model into production.
You want to monitor or observe performance drift, outlier bias, etc. and analyze those results to insert the model. Performance management is a framework that helps establish a feedback loop in the ML lifecycle. Through this, you're always ready to receive feedback from learning models in production to troubleshoot faster, and improve performance. So basically, when you are in step five, maybe you want to retrain and you go back to step one.
Now imagine adding fairness to this performance management model. Throughout a life cycle, you will continuously and cautiously measure bias in the model to always be responsible. This is something you need to continuously monitor as with bias and fairness, a model can be biased later after being deployed in the production.
Bias Detection in Modelling
For our model, we decided to select fairness metrics that we think are like widely used and that have been effective coverage, including disparate impact. Disparate impact is a form of indirect and intentional discrimination in which certain decisions disproportionately affect members of a protected group. Similarly to this, you have demographic parity and we decided to use both.
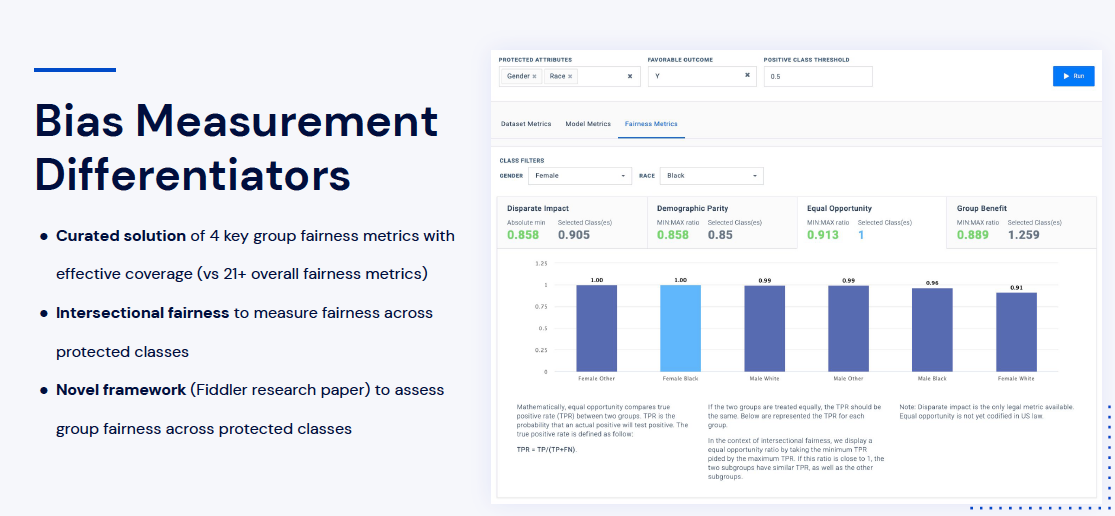
The disparate impact of demographic parity that compares if the proportion of each segment of the protected class received the positive outcome at equal rates. Then we have equal opportunity, which is based on the true positive rate, and it means that all people should be treated equally or similarly and not disadvantaged by prejudice or bias. After this, we then have good benefits, which is to measure the rate at which a particular event is predicted to occur within a subgroup and compared to the rate at which it actually occurs.
As an example, you have equal opportunity. So if you look at the bar chart (below), it represents potential equal opportunity for the true positive rate values in each subgroup.
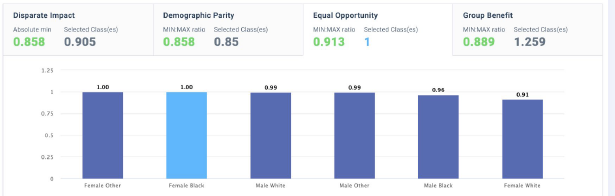
Then in green, you have the index ratio, which is taking the minimum by the maximum value. A good rule of thumb is to consider that we usually use is below 0.8. In addition to those, you have fairness metrics to ensure we didn't introduce some possible bias with the data.
Through this model, we allow for the below bias measurement differentiators:
- Real-time Fairness - Measure fairness on production data as well as on static datasets
- Integration into Modelling - Receive real-time fairness alerts and address the issue when they matter
- Built-in Explainability - Understand the impact of features to specific fairness metrics
- Risk Mitigation - Track back to any past incident or analyze future predictions to minimize risk
You can see the whole talk from Léa Genuit below:
Learn more at the upcoming AI Ethics Summit, taking place in February in-person in San Francisco on 17-18 February. View the agenda here.
