
There has been an exponential growth of data sets that measure cellular biology & the activity of compounds over the last 5+ years; enough to feed and encourage the use of Machine Learning algorithms such as that of Deep Learning (DL). Whilst gaining impressive traction across a range of applications, DL is well known for its remarkable progress in image recognition.
Specific to pharmaceutical research, Deep Learning provides an ability to mine through extensive biomedical data sets and is paving the way toward alleviating the low success rate in pharmaceutical R&D as well as shortening the tunnel process of drug development - leading to faster medicinal solutions from the very first diagnosis of disease. This blog, part of the DL Explained Series, explains some of the key areas of DL used in the advancement of drug discovery alongside video presentations and detailed diagrams.
TL;DR:
- Robust Deep Image Embeddings uses visible cell proteins & fluorescent dye to record abnormalities
- CNN receive information from input layers on images and pass it through multiple convolution layers which contain 2D feature maps
- Metric Learning is also used, utilising a triplet network. Rather than trying to determine the class that an object falls into, the network learns a way of representing the distance between the embeddings on medical imaging
- Watch a video presentation of how DL is used in Medical Imaging here
Robust Deep Image Embeddings
There's a fundamental difference in the physical appearance of cells in healthy individuals compared to those that have inherited rare diseases. For diseases that operate on a cellular level e.g. Cornelia de Lange syndrome, these differences are visible in the cell proteins by applying a dye that adheres to them. Once activated at a certain wavelength of light, the stains will become fluorescent and can be recorded in image form. Drug research may require running 300+ cell populations on a single plate whilst looking at 100-200 plates a week. That generates roughly 125-250,000 images - how are they all processed in time?
Image Segmentation
A process of breaking up the digital image into labelled sets of pixels to create segments or image objects. These highlight contours, boundaries, colours, textures and more within the image.
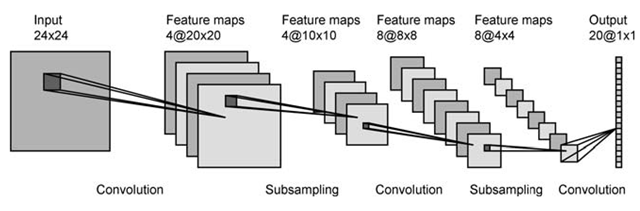
The Convolutional Neural Network (CNN) is a type of Deep Learning Neural Network and is used in image segmentation. The CNN receives information from the image via the input layer and passes it through multiple convolution layers which contain 2D feature maps. At each stage the width and height are convoluted against a field of parameters before reaching the final stage where the neurons are connected across layers to generate an output in the form of labelled pixels. Each subsampling layer serves to reduce the size of feature maps before further convolution. In a general example, the output of segmentation shows:

However in drug discovery, image segmentation may look a little more like this:
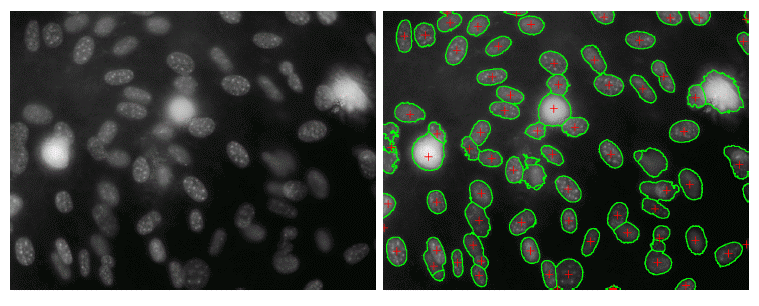
Here the CNN has segmented the image to show which pixels represent the edges of each cell (green).
CNNs are also used in Image Classification - a process which, for example, would determine whether an object is classified as a cat, a dog or a horse. However, in medicine, the number of classes in the data set would grow exponentially as new drugs and diseases are discovered over time. Instead, a process called Metric Learning is used.
Metric Learning
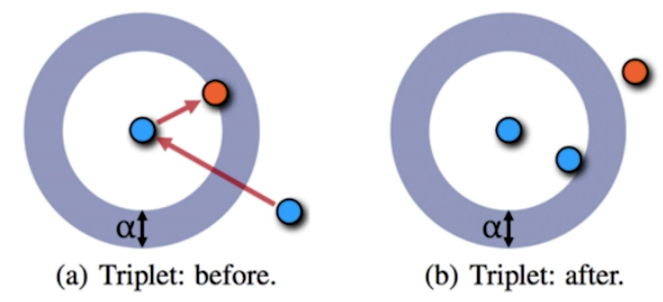
Metric Learning is an approach of Deep Learning/CNN that uses a triplet network. Rather than trying to determine the class that an object falls into, the network learns a way of representing the distance between the embeddings. For example, rather than just feeding in an image of a dog and having the network determine a 'yes or no' classification, you would feed in images in triplets: one image to serve as the base (blue, e.g. Labrador), another that is similar (blue, e.g. Retriever) and the last as a completely different example (orange, e.g. cat). The output/loss function of the network would be that the two similar images are closer in distance than they are to the dissimilar image.
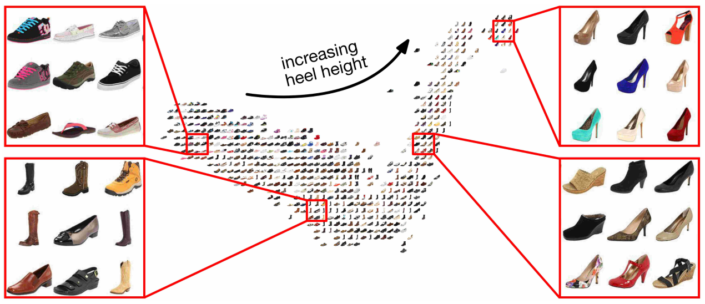
Similar examples should have smaller distance than different examples by some margin, e.g. in the photo below, heeled shoes are clustered together & far away from flat shoes.
Metric learning is beneficial in medicine because it can provide a smaller distance between the cells with healthier proteins amongst those that have a malfunction, it can group images on the basis of similar treatments, it can identify cells by specific disease despite personal genetic differences & so on.
However, what about nuisance factors or experimental conditions? A cell undergoing treatment changes physically over time - how does the network still provide a small distance (high similarity) for one to recognise that it's still the same cell despite its physical differences over a two week treatment period? The answer is to ensure that nuisance factors/experimental conditions in these images are all labelled so the exact week or batch of experiment an image comes from is known. Suppose xk is an image of treatment, with k being a nuisance factor. The CNN would need triplets of the xk form as mentioned previously, e.g.
x = (base) image of cell undergoing treatment
xk = (similar image), e.g. same treatment class but (k) different week
xk = (different image), e.g. different treatment class but (k) same week
The message this labelled data then sends to the network is to focus on the inter-nuisance factor similarities and intra-nuisance factor differences. A similar result was seen in Google's FaceNet, which was able to draw up smaller distances between the same person who looked extremely different in adverse lighting:

The growth of data sets that measure cellular biology have allowed us to train CNNs to quickly recognise the similarities between cell properties, thus serving as exceptional tools in drug discovery. Having already covered so much ground, the future of drug discovery with this technology in place looks promising!
The above information is cited from RE•WORK's AI in Healthcare summit as presented by Mason Victors, Chief Product Officer at Recursion Pharmaceuticals.
Interested in reading more leading AI content from RE•WORK and our community of AI experts? See our most-read blogs below:
Top AI Resources - Directory for Remote Learning
10 Must-Read AI Books in 2020
13 ‘Must-Read’ Papers from AI Experts
Top AI & Data Science Podcasts
30 Influential Women Advancing AI in 2019
‘Must-Read’ AI Papers Suggested by Experts - Pt 2
30 Influential AI Presentations from 2019
AI Across the World: Top 10 Cities in AI 2020
Female Pioneers in Computer Science You May Not Know
10 Must-Read AI Books in 2020 - Part 2
Top Women in AI 2020 - Texas Edition
2020 University/College Rankings - Computer Science, Engineering & Technology
How Netflix uses AI to Predict Your Next Series Binge - 2020
Top 5 Technical AI Presentation Videos from January 2020
20 Free AI Courses & eBooks
5 Applications of GANs - Video Presentations You Need To See
250+ Directory of Influential Women Advancing AI in 2020
The Isolation Insight - Top 50 AI Articles, Papers & Videos from Q1
Reinforcement Learning 101 - Experts Explain
The 5 Most in Demand Programming Languages in 2020