
Author: Gerben Oostra, Big Data Architectures
In the business to consumer market, there are two strategies to grow market share: gaining new customers, and retaining existing customers. The latter challenge is referred to as preventing churn. So churn rate, or even better, retention rate is a key performance indicator. What is a good way to approach this challenge with machine learning?
As company leadership it might be tempting to quickly gather your best data scientists and put them to work. And as one of those lucky data scientists, it is tempting to quickly get your hands dirty. The goal is to prevent churn, we know how to create a predictive model, so why don’t we create a model that predicts who is going to churn?
Predicting churn?
Even though it is possible to make a really good model that predicts who is going to churn, it won’t help you. Really, creating a model that predicts who is going to churn is not what you should do.
A machine learning model does not exist on it’s own, it is part of a bigger system. Even though a data scientist can apply a powerful attention network and get perfect precision, that is just one part of the whole.
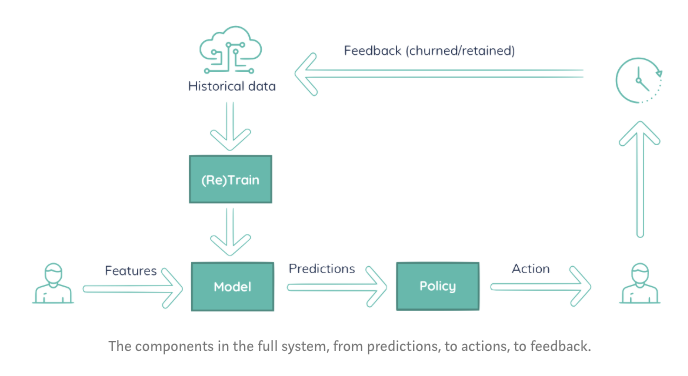
The output of the model is input for some business process, someone taking actions. For example, a marketing department which will determine offers or run creative campaigns to keep those customers.
This separation of concerns results in a local optimum. The scientist predicts who is going to churn. A marketing department determines how to retain them. And that’s the issue. The problem is divided into two separate problems, solved by different teams, resulting in local optimal solutions.
Actionable predictions
The data scientist should get to know and stay in contact with all relevant business units to find out the bigger picture. To know the actual actions finally taken, and based on which input. With that bigger picture, it is possible to determine relevant predictions as close as possible to the final action. Actionable predictions.
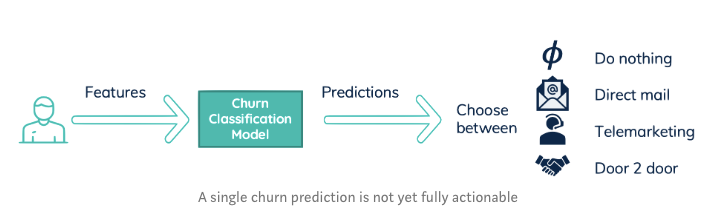
Thus instead of predicting who is likely to churn, and leaving campaign effectiveness to the marketing department, we need to predict how we can best retain each individual user.
The marketing department is good in designing campaigns. The data scientists are good in using historic data for predictions. Thus let the marketing department design campaigns. And let the data scientists predict how well they work. With such a setup the action is almost directly predicted.
Predicting uplift
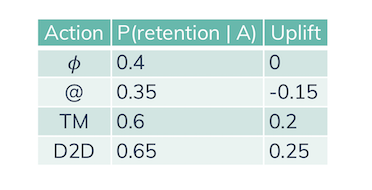
When applying campaigns there is always 1 default action: doing nothing. Possible other “actual” campaigns could be to send out certain emails, call them, or even visit them. We want to know how well applying a campaign works compared to doing nothing. The resulting “difference in retention probability” is called uplift.
There are different ways to model uplift, of which one general approach is the Transformed Outcome. The further reading section has some pointers.
Business impact
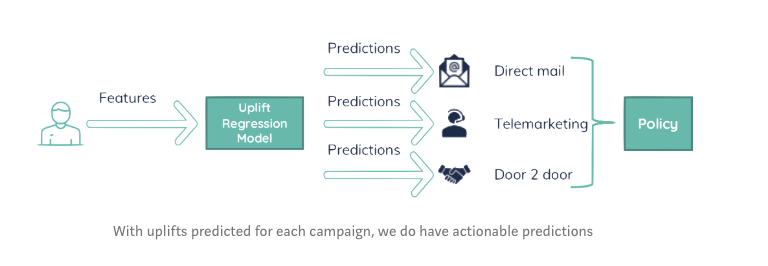
Uplift is the most direct prediction of the impact on the KPI (retention). The business impact actually includes two other aspects: the customer lifetime value (CLV), and the cost of the campaign. Retaining a user is not something we pursue for any arbitrary cost. The predicted uplift thus needs to be modified into “Net result”, combining the uplift with the CLV and campaign cost.
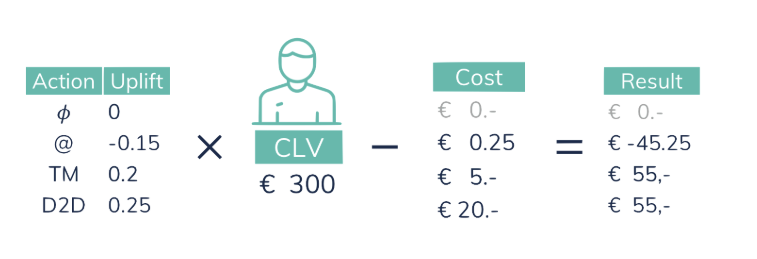
The data science team is responsible for creating a causal model, predicting the uplift of every possible action. The marketing department is responsible for defining those actions. This, combined with financial impact, can be used to effectively drive business impact.
Further challenges
So far we’ve only created a problem definition, but did not provide any details about how to solve it. For a quick (10 min) explanation, please watch my presentation from the RE•WORK Deep Learning Summit in London here.
There I will dive more into two topics:
- How can we create a causal model?
Here we move from correlation to causation. We are not interesting in who was retained by old campaigns, we want to predict if customers are going to be retained. - How do we balance exploration & exploitation?
We want to utilize (exploit) campaigns which we know that work, but how about new campaigns?
Further reading
Interested in diving into some of the techniques yourself? Then you might find the following interesting:
- The transformed outcome paper: Athey, S., & Imbens, G. W. (2015). Machine learning methods for estimating heterogeneous causal effects. stat, 1050(5).
- Uplift modelling (like in pylift, with also a more simple explanation of the Transformed Outcome)
- Causal inference. Check this introduction post on causal diagrams, and this blog by Uber on mediation modelling, and one by Uber on causal inference in general.
- Inverse propensity weighting/ inverse probability scaling, like this blog on the underlying intuition.