
Detecting anomalies in time series data has become an interesting field of research over the last several decades. This field detects irregular or unexpected patterns throughout time intervals; patterns that often contain meaningful information and may even indicate threats or erratic behaviors in various scenarios and applications. Here at Slice, we detect anomalies present in abnormal receipt transaction counts and price irregularities for merchants over time. Some of these anomalies are critical and require urgent identification and processing, so we can ensure high-quality data products to delight our clients.
Although various kinds of anomaly-detection algorithms exist, none of them generalize well across all types of time series datasets. Here at Slice we collect ecommerce data for thousands of merchants, each with different behaviors and trends. To succeed in our task, it is critical to create a system that can generalize across all of these different merchants.
With our priority being to improve prediction accuracy, we decided to combine two different approaches (each with their different strengths and weaknesses) with an ensemble method.
The first approach, a Generalized Additive Model (GAM), combines various trend components, such as cyclicity, seasonality, and trends, through non-linear smoothing functions.

GAM’s standard optimization algorithm, known as backfitting, has some disadvantages associated with additional hyper-parameter tuning. Therefore we use Limited-memory BFGS instead to optimize the loss function of the likelihood estimate, defined below:
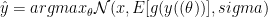
We also explored a Generalized Multiplicative Model (GMM) defined as:

However, for our task, we found the predictions of GAM to be smoother with greater accuracy than a GMM.
The second approach uses Deep Learning, a new popular approach with unique abilities to learn complex non-linear functions without requiring considerable feature engineering. Recurrent Neural Networks (RNN) focus on sequence modeling and utilize memory blocks such as Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU).
Our neural optimizations, represents a sequence modeling approach based on two-layer RNN with dropouts. It exploits the space of different combinatorial variations by weighing and transforming the inputs and predicting the next observation in the sequence. Small datasets with regular RNN activation neurons perform reasonably but one must be careful, because as the size of the data grows, the usage of LSTM or GRU cells becomes more critical for learning context.

The above diagram demonstrates a two layer dynamic, feedforward RNN. Each input is an observation represented through an embedding vector of size ‘k’. The network predicts one step ahead of the time of the next observation in the sequence.
Our ensemble approach then makes the final prediction by comparing the outputs and anomaly overlap between both approaches.
In addition, we estimate confidence intervals and uncertainty for each approach based on the distribution of predicted probabilities and simple statistical methods.
In order to measure prediction error we used Symmetric Mean Absolute Percentage Error( SMAPE) evaluation metric:

Let’s take a look at two examples using both approaches on mock datasets. For privacy reasons, the examples provided below are not real use cases at Slice and were generated for this blog post.
The first example shows sales growth of a product ‘X’ throughout a time series stretching from 2012 to 2017. It exhibits linearly growing trend and annual seasonality shaped as an upside down parabola.

The sales growth of product ‘X’ from 2012 to 2018
The predictions are made starting from 2017 and the rest of the data is used for training. We can see that both approaches are capable of predicting growing trends, seasonality and cyclicity with slight differences in their forecasts.


Predictions using RNNs in orange.
The second example demonstrates sales trend of a product ‘Y as a stationary time series. Overall, the observations look randomly distributed except for the high spikes we see occurring annually.

The sales trend of product ‘Y’ from 2012 to 2018
What if in 2017 we see an unexpected, possibly anomalous, growth of sales for a particular time period?
Well, we can see from the examples that both algorithms predict the spike, and they forecast lower sales in the time range displaying the unexpected growth. These cases are then detected and marked as anomalous using the evaluation metric mentioned above.
It is important to note that we observe slightly shorter forecasted spikes using the regression model, whereas the neural net suggests small, unexpected, additional spikes for the given example. These spikes suggested by the deep learning model are associated with the sequence modeling nature of the RNNs and could be corrected by tweaking the hyper-parameters.


Predictions using RNN model in orange.
Conclusion
We just discussed two approaches for anomaly detection in time series, generalized additive regression models and recurrent neural nets. Each of these approaches has its advantages and disadvantages.
RNNs take into consideration the sequential interdependencies between observations; however, they have disadvantages related to error propagation (since the prediction at the current timesteps is based on the predictions at the previous timesteps).
Regression models are less computationally expensive compared to RNNs and have the flexibility to incorporate any type of smoothing function into the model. Nonetheless, they have challenges associated with explicitly defining functions (e.g. to capture cyclicity, seasonality, and trends) and estimating ideal smoothing parameters.
Overall, an ensemble approach based on both worlds allows us to make reliable predictions for various types of time series, even if the data is very small, noisy, and with barely recognizable patterns.