
Many times AI has been put on a pedestal as the future of x y & z, however, many seem to agree that education is a sector in particular which will see stark changes in both admin, teaching styles, personalisation and more. I had the pleasure of speaking to three individuals working in the field, including, Vinod Bakthavachalam, Senior Data Scientist at Coursera, Kian Katanforoosh, Lecturer at Stanford University & Sergey Karayev, Co-Founder and CTO of Gradescope.
AI Assistance for Grading Handwritten Free Responses
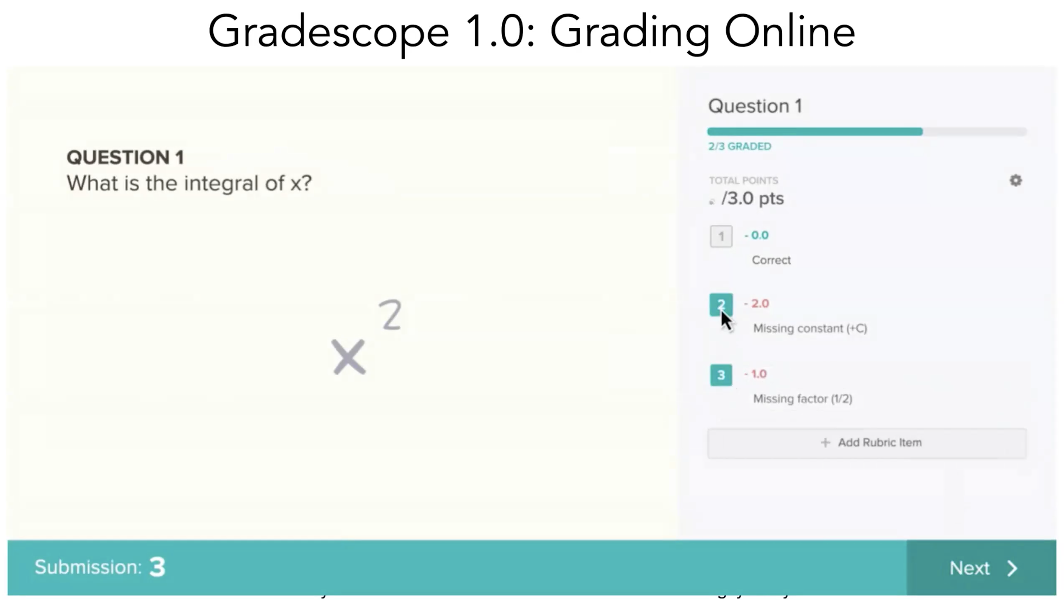
We began by having Sergey of Gradescope walk us through his product, which has been recently acquired by turnitin. The concept, it seemed was formed from the simple and widespread issue of both lack of consistency, lack of insight through time constraint and delayed feedback on academic work. Sergey focussed then on solutions for these frustrations. Sergey found that scanning the papers onto an online interface when paired with a rubric can allow for accurate marking in seconds across several papers. This also allows for adjustment from the marker (figure one). Changing the points based system of the rubric, then retroactively applies it to the paper markings. This rubric, Sergey suggests also works as feedback as the student is able to see exactly why they are losing points on each question.
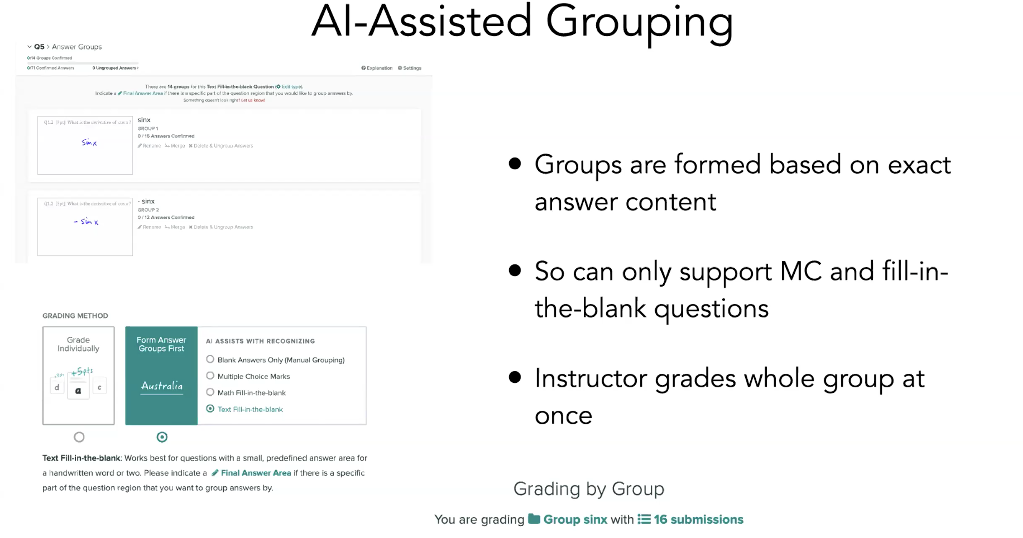
Following this, Sergey decided to create an AI assisted grouping technique utilising Machine Learning. The core idea being that if they can analyse exactly what it is the student has written, they can put all the answers that say the same thing into groups which is then marked together using the aforementioned method. The criteria for AI-Assisted grouping is shown below:
Of course, the question arises, what is it that instructors are actually grading? multiple choice or written answers? Sergey suggested that through working with Berkeley professors, they were able to build an interface with 25k annotations of binary, multiple choice, short writing, medium writing, long writing and drawing types. What is the right user interface though for AI Assistance for short answers? You can't simply group them as they are too high-dimensional and are not mutually exclusive. Another option would be to use answers searching, however, searching keywords is not AI... It was then decided that answer sorting was the right course, using answer sequences to deter patterns in the data.
Sources of complexity
Sergey then went on to discuss the main sources of complexity found in his work which included handwriting, variation of answers and creating the rubric itself. Some rubrics are just correct/not correct whereas others can be more complex.
Handwriting in general can be a sticking point, not only in education but in various scenarios, evidenced by Sergey in his reference to a study from the UAE citing poor and ilegible handwriting as the cause of 7k deaths per year.... In STEM, however, there is increasing complexity due to the diagram, math and science notation, code and arrows/cross-outs etc. In regard to complexity, Sergey has tested on the Microsoft API with a best performance of 17% which led to their in-house creation of a convnet + transformer which is better and still improving. This system is being tested on both handwriting-like synthetic examples but also whole images using attention to line-by-line to follow. Sergey noted that once handwriting complexity is sorted, there still lies the issue of answer complexity - citing the standard NLP issue of there being a thousand ways to say the same thing.
The crucial point of his work, Sergey suggested is two fold. The decrease in need for marking time allows for not only greater time with students, but also greater allowance for detailed feedback and insight into learning.
AI Career Pathways
Next up we heard from Kian Katanforoosh, a technology entrepreneur and lecturer at Stanford University, where he teaches Deep Learning in the Computer Science department with Prof. Andrew Ng. He is also the founder of Workera, a company that measures the skills of data scientists, machine learning engineers, and software engineers, and serves them AI career opportunities, and is a founding member of deeplearning.ai.
Kian opened by discussing a framework for mentorship, citing the criteria that they would discuss:
- Where you are at right now
- Where do you want to go (aspirations)
- Using these options, they should be able to design and recommend a path for you
Why is this relevant? Well, to build a self-assesment, Kian explained that you must first understand the tasks which those are doing in the field. Kian and his team found, through surveys of 100 organisations two types of organisations:
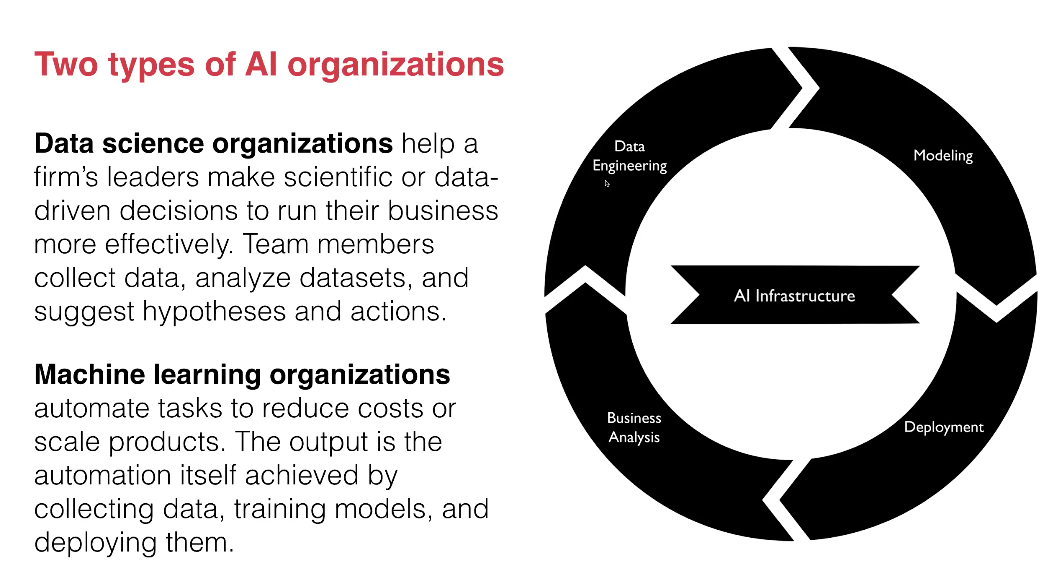
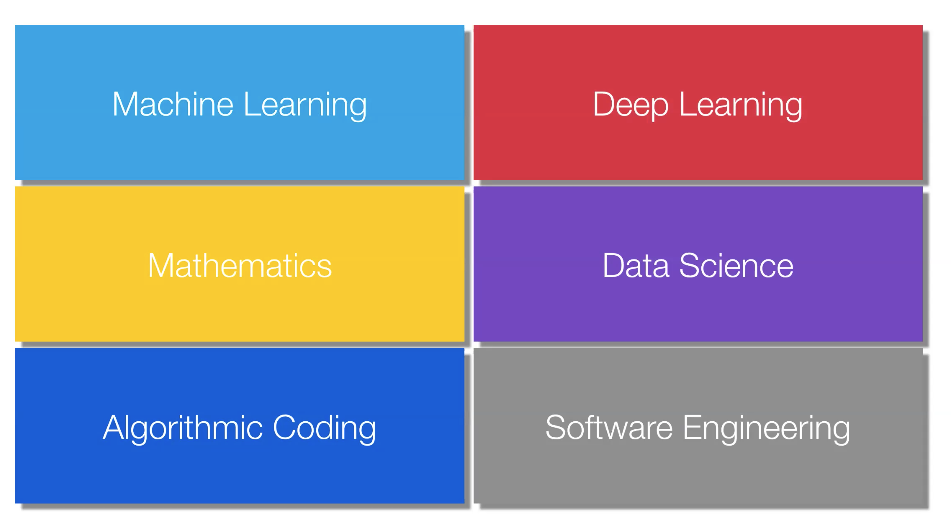
Task wise, Kian suggested that there are roles, examples of these and the sub tasks included - looking specifically at Data Engineering, Modeling and Deployment/Business Analysis. Kian suggested that once you have these points understood, the second step is to determine the skills needed for said roles. These were simplified drastically, showing six standout areas (most of which apply to more than one 'task').
"Typically the ML, Deep Learning, Mathematics and Data Science skills are those you leverage in modelling whilst the software skills are mostly for data engineering and AI infrastructure/deployment tasks"
Now that they have the areas, Kian suggests you need to write the assessment. In order to write an assessment, you need to have a grading rubric as shown below, the example used being for a Machine Learning test.

On top of the above skill specification, an individual must pass a skill checklist and pass a QA process to enhance the test validity. Now that you are able to evaluate at scale, you can then analyse existing career options for specialisation. To determine this, Kian and his team looked at the software industry where engineering teams have figured out how to form and slip their teams, generally seen split into the below:
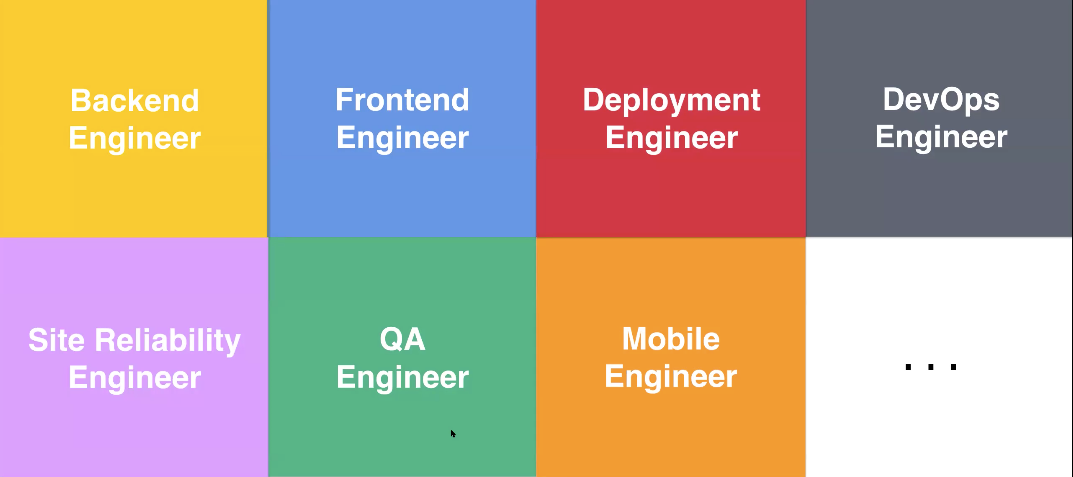
AI teams, however, are not as well understood. Through a survey, Kian used the above roles & data to split into each 'task' and the extent to which each is prevalent in particular roles:
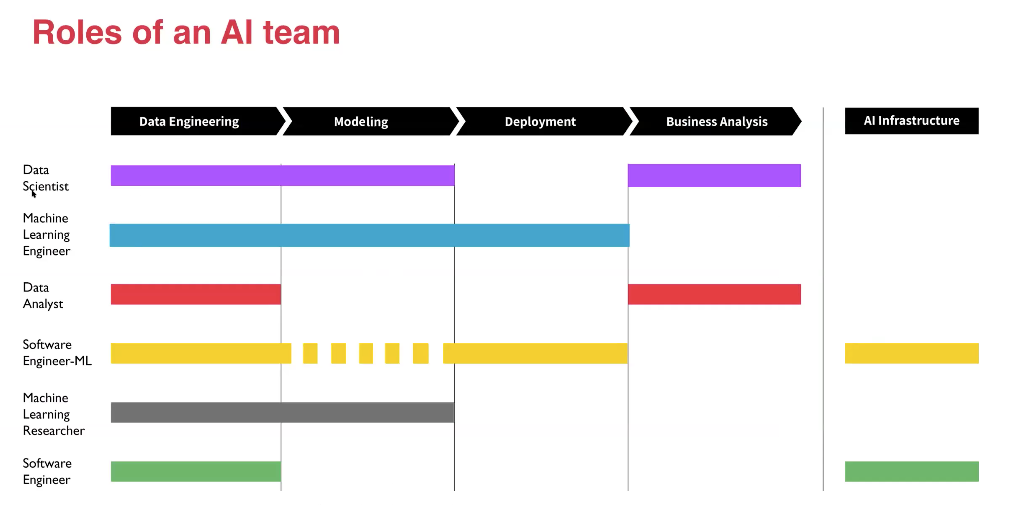
Finally, once they are able to evaluate, they can then access mentorship accurately at scale for each individual. To do this, they have built an actionable feedback system leveraging both the evaluation and estimation. This can be at the skill level, recommending content for the individual to learn which is very accurate, recommending courses at section-level through which workera can create a skill learning calendar with regular evaluations to adjust the outcome. Finally, workera can then recommend a career track with incredibly accurate results. This can then be broken down to a great degree, further strategising learning to bridge any gaps that may need filling for the desired role.
Using Word Embeddings for Scaling Access to Online Education during COVID
It was then the turn of Vinod Bakthavachalam, Senior Data Scientist at Coursera to discuss the use of word embeddings for scaling access to online education during the COVID-19 pandemic. To start his talk, Vinod showcased the extent to which the COVID-19 pandemic has affected education, with 1.2 billion estimated affected learners. Their solution to this? Coursematch! Vinod went on to explain that Coursera's coursematch uses ML algorithms to ingest School's on campus course catalogue to match them to online courses in replacement of their cancelled courses.
The data for this included 1,800 schools' catalogue, with 2.6+ million school courses matched to date. Vinod then gave a tutorial of how this open source tool actually works. Through typing in the institution name, it list all courses available as standard, alongside those offered by coursera, also including a degree of match. Individual course pages are then visible.
Vinod then peered under the hood on this model further, explaining that it is powered by Word2Vec, a neural network model which learns vector embeddings for words using surrounding context in text. This text can then be converted to Math, allowing for greater levels of comparison.
The NN architecture for training a Word2Vec model was then explained alongside the information needed to do so:
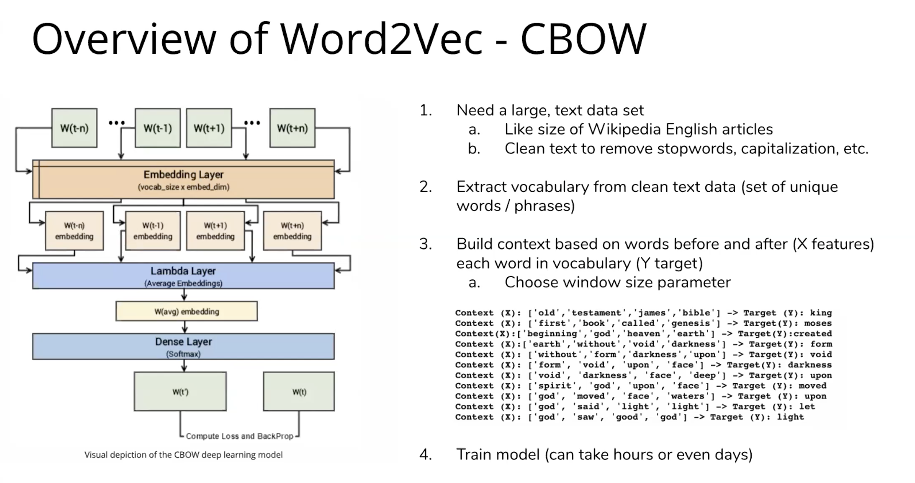
Vinod then gave a greater overview of the process as a whole:
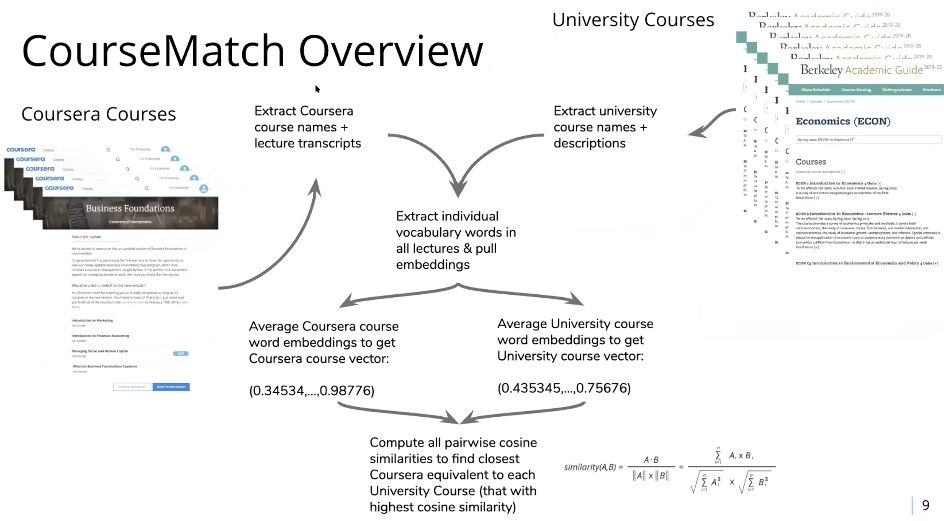
From this research and application through models, Vinod finished with his three main tips for utilising his model:
- Leverage open source word embeddings from Google News, Facebook, Wikipedia etc and packages (Gensim) to start quick
- Build a general embedding infrastructure/set of utilities to power downstream applications
- Anything requiring "recommendations/similar products" can benefit greatly from leveraging similarity in embeddings
Interested in reading more leading AI content from RE•WORK and our community of AI experts? See our most-read blogs below:
Top AI Resources - Directory for Remote Learning
10 Must-Read AI Books in 2020
13 ‘Must-Read’ Papers from AI Experts
Top AI & Data Science Podcasts
30 Influential Women Advancing AI in 2019
‘Must-Read’ AI Papers Suggested by Experts - Pt 2
30 Influential AI Presentations from 2019
AI Across the World: Top 10 Cities in AI 2020
Female Pioneers in Computer Science You May Not Know
10 Must-Read AI Books in 2020 - Part 2
Top Women in AI 2020 - Texas Edition
2020 University/College Rankings - Computer Science, Engineering & Technology
How Netflix uses AI to Predict Your Next Series Binge - 2020
Top 5 Technical AI Presentation Videos from January 2020
20 Free AI Courses & eBooks
5 Applications of GANs - Video Presentations You Need To See
250+ Directory of Influential Women Advancing AI in 2020
The Isolation Insight - Top 50 AI Articles, Papers & Videos from Q1
Reinforcement Learning 101 - Experts Explain
The 5 Most in Demand Programming Languages in 2020