
When most people think of investment banking and trading, they think of a firm filled with suit-and-tie bankers frantically running while yelling trades and cuss words at each other. Some imagine a scene straight out of the Wolf of Wall Street, of complete chaos. The reality is that this couldn’t be farther from the truth. On an average day for hedge fund Citadel Group, it’s eerily quiet, despite executing more shares each day than the New York Stock Exchange itself! Meet the new wall street traders, high-frequency algorithmic trading platforms.
For traders at Citadel, work can be far different from what most people expect. They only monitor trading platforms for any problems, and no trading is conducted by humans!
Algorithmic Trading Systems and How They Work
These strategies are being used by almost every single hedge fund, investment bank, and private equity firm, and has become the standard for investment banking. Two Sigma, a hedge fund relying solely on machine learning solutions for investments handle over $50 billion in assets, making it the 3rd largest hedge fund in the world. While algorithmic trading, or the use of computerized systems to automate trading decisions, has been widely used in the finance industry for nearly 30 years, recently a major factor has come into play: artificial intelligence.
Before, these algorithmic trading platforms had to have specific rules for when to buy and sell shares and how to allocate investments. If a programmer left out any integral rules, it could result in millions in lost dollars. With machine learning and natural language processing, these models no longer need to rely on specific rules and can form patterns on what values certain financial indicators of high-performing stocks tend to have, and much more. However, as a result of machine learning, the architecture of these automated trading systems has undergone major changes.
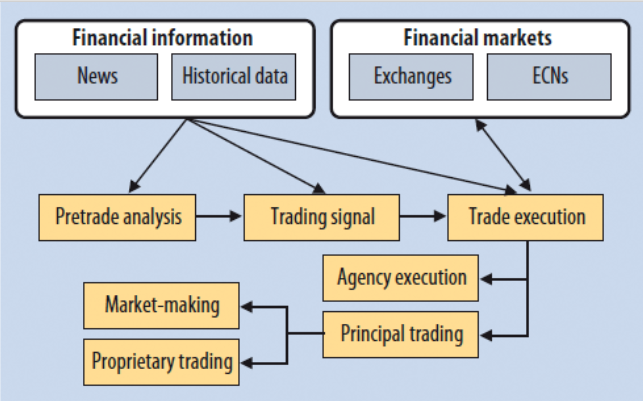
A Basic Layout of A Algorithmic Trading Platform
The Basic Layout of an Algorithmic Trading Platform
Most algorithmic trading platforms utilize financial information from historical data, such as the stock price, financial indicators, and more, to help build a pre-trade analysis. With the use of natural language processing, many platforms now also utilize financial market news from top firms such as Thomson Reuters, Bloomberg and more, to be read and assign sentiment, or determine whether the news can be deciphered as good or bad. Using this, our platform can form a trade signal (buy/sell/hold), and execute a trade onto an exchange or electronic communications network (ECN). These platforms have become standard practice at all banks and firms, with over 70% of trades being conducted through computers.
Realizing the huge potential machine learning has in this industry, I decided to grow my skills by developing a deep learning model to predict stock prices on the S&P 500 using time-series historical data from the Google Finance API and Kaggle.
How I Created My Own Price Prediction Model
Realizing the huge potential machine learning has in this industry, I decided to grow my skills by developing a deep learning model to predict stock prices on the S&P 500 using time-series historical data from the Google Finance API and Kaggle. A regression model worked best for this as the model would output a numerical value for the future price of a stock, as well as a probability of how confident it felt with the prediction.
Designing the Network Architecture
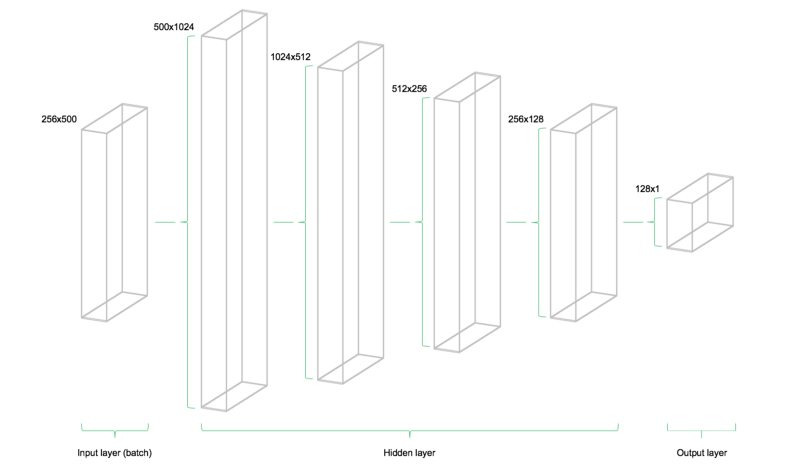
A Technical Illustration of the feedforward Network Architecture
My model’s architecture is pretty simple and is modeled off of several research papers and personal projects, especially this excellent paper written by some researchers at the Department of Electrical Engineering at Stanford. The image above, represents the architecture, as it shows that each batch of data only flows from left to right. Using this paper, I decided to use the mean squared error (MSE), a simple way to generate a measure of deviation between the model’s prediction and actual training targets.
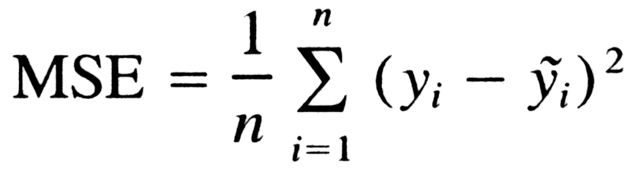
MSE is a simple yet effective way of obtaining the cost function of the network.
The input of the model consists of a two-dimensional matrix, while the outputs are a one dimensional vector. These placeholders serve the purpose of fitting our model, as X is the input, or the stock prices of all stocks under the S&P 500, while Y is the output or index value of the S&P 500 one minute into the future.
# PlaceholderX = tf.placeholder(dtype=tf.float32, shape=[batch_size, number_stocks])Y = tf.placeholder(dtype=tf.float32, shape=[batch_size])Using Dropout to Prevent Over-Fitting and Improve Accuracy
Dropout is a technique for regularization in machine learning models to prevent neural networks from overfitting. Overfitting is essentially when the model will model training data to well. It learns the detail and noise in the training to an extent that it negatively impacts performance on new data, such as the test and validation set. It works by selecting random neurons which are then ignored, or “dropped out”, randomly. Any updates to the weights of the model, as well as the ignored neurons contribution to the forward pass, are not applied to the neuron in backpropagation. This forces other neurons to have to “step in” and handle any representation required to make predictions for the missing neurons. This creates multiple independent internal representations being learned by the model and causes the network to become less sensitive to the specific weights of neurons. The network is able to become more capable of generalization and less likely to overfit. I incorporated this into all four hidden layers of the model, as shown below, which helped lower the test mean squared error. The dropout rate used was 50% or 0.5, meaning through each iteration, half of the neurons are randomly “dropped-out”.
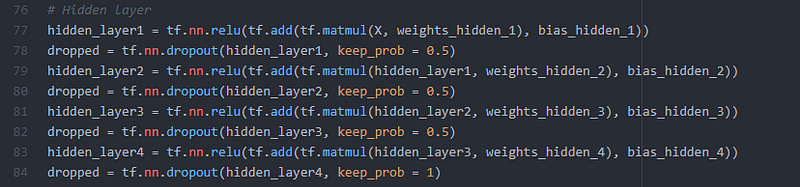
Implementation of dropout throughout the hidden layer
How I Trained the Model
The model uses data compiled in a .csv format, consisting of minute-by-minute data of the 500 stocks as well as the stock index’s performance on the S&P 500. Luckily, the data used was already cleaned and prepared, with the last observation carried forward, meaning any missing data in the table would carry over the previous observation. 80% of the data was devoted to training with the rest used for testing the model.
Displaying the time-series data using pyplot.plot(data['SP500']):
After importing the data, defining the placeholders, variables, cost functions and AdamOptimizer, the network was trained through mini-batch training. This is where we take random samples out of the dataset and feed it into the network. A batch of data, Y will flow through the network’s hidden layers until it reaches the output layer, where it is compared to the target data, Y , in the current batch. Using the optimizer and cost function, the model updates its parameters, such as it’s weights and biases. This repeats with each batch of data. One full iteration throughout all batches is known as an epoch.
The Results
The model’s performance on the test set, or the 20% of data set aside which is not learned, but set aside. To visualize the results, I took the performance on every fifth batch, and combined it into an animation of the training process. The final test MSE reaches 0.00141, due to the target being scaled, while the absolute percentage error is 7.57%, a pretty decent result. Through utilizing things such as the dropout rate and having a criteria for stopping the model, this is far better than original test results, but there are many other ways we can optimize the model’s performance. When we look at the results in the animation below, we can see that as the model runs through more and more batches of data, it begins to learn the patterns of the data set and more accurately predict the price of the stock index until it closely mirrors the target data.
Conclusion
Hundreds of millions of trades are conducted per minute using algorithmic trading platforms. With the additional implementation of artificial intelligence, specifically machine learning and natural language processing, its use in the stock markets will only continue to expand. While algorithmic trading is one of the key causes of the dwindling number of traders at most firms and exchanges, as the industry moves towards automation, the use of AI suggests something else; a lower need for analysts and investment bankers. At top firms, such as Goldman Sachs, the number of analysts has been consistently on the decline, while the need for engineers has gone up, to compete with top hedge funds such as Two Sigma and Citadel. Machine learning is arguably going to significantly disrupt this industry. The financial industry is likely going to need more tech-based employees than ever before. Because of this, it is more important than ever before that people entering the industry are knowledgeable with programming and technical skills. However, there is one positive takeaway to the loss of investment banking jobs in our future; an influx of fintech startups and firms promising more transparency and control in the hands of investors, and a chance to level the playing field for any investor who wishes to enter the industry.
Key Takeaways
- Algorithmic trading accounts for the majority of shares sold in today’s world, and controls the market.
- With the recent implementation of AI into these platforms, we no longer need to program specific buy/sell rules, and rather allow for these models to learn patterns and make decisions on it’s own.
- Algorithmic trading platforms use an ensemble of models, such as NLP-based models for sentiment analysis, and regression models for future stock prices to generate a trading signal.
- The use of AI in algorithmic trading signals will likely disrupt the investment banking industry and result in a need for more developers.
Next steps
If you enjoyed this article, be sure to follow these steps to keep in touch with my future projects and articles!
- Be sure to give my article some claps for support.
- Connect with me on Linkedin, to hear about my future developments and future projects. Right now I’m currently working on using DeepBind to predict sequence specificities of DNA and RNA-binding proteins!
- Be sure to subscribe to my monthly newsletter to see new projects, conferences I go to, and articles I put out!
- Feel free to email me at [email protected] to talk about this project and more!
Thanks for reading this article, I hope you gained something from it, and learn more about the power of AI in the investing industry!